

Heutzutage haben die Verbraucher:innen mehr Auswahl als je zuvor. Sie können ziemlich alles bekommen, was sie wollen und wann immer sie wollen. Mit der steigenden Nachfrage nach digitalen Services und Entertainment ist der Wettbewerb auf dem App-Markt härter als je zuvor.
Um wettbewerbsfähig zu bleiben, ist es wichtig, immer einen Schritt voraus zu sein. Und genau das ermöglicht die prädiktive Modellierung: Sie hilft Marketers, Verbraucherverhalten und Trends zu verstehen, künftige Aktivitäten vorherzusagen und ihre Kampagnen auf datengestützten Entscheidungen zu planen.
Prädiktive Analysen gibt es schon seit Jahren, und sie werden von den weltweit größten Unternehmen eingesetzt, um ihre Prozesse zu perfektionieren, Angebots- und Nachfrage-Veränderungen zu antizipieren, globale Veränderungen zu prognostizieren und historische Daten zu nutzen, um sich besser auf zukünftige Events vorzubereiten.
Sie fragen sich, was diese seltsame Kombination aus Data Science und Marketing eigentlich ist?
Die prädiktive Modellierung ist eine Art der Analyse, bei der maschinelles Lernen und KI zum Einsatz kommen, um historische Kampagnendaten, Daten zum früheren Nutzerverhalten und zusätzliche Transaktionsdaten zu untersuchen und zukünftige Aktionen zu prognostizieren.
Mithilfe der prädiktiven Modellierung können Marketers schnelle Entscheidungen zur Kampagnenoptimierung treffen, ohne auf die tatsächlichen Ergebnisse warten zu müssen. Beispielsweise hat ein Algorithmus für maschinelles Lernen ergeben, dass Nutzer:innen, die innerhalb der ersten 24 Stunden Level 10 eines Spiels abgeschlossen haben, mit 80 % höherer Wahrscheinlichkeit innerhalb der ersten Woche einen In-App-Kauf tätigen.
Mit diesem Wissen können Marketers nach Erreichen des Events innerhalb von 24 Stunden eine Optimierung vornehmen, noch bevor die erste Woche vorbei ist. Wenn die Kampagne keine gute Performance erzielt, wäre eine weitere Investition eine völlige Verschwendung des Budgets. Sollte dies jedoch der Fall sein, kann eine schnelle Verdopplung der Investitionen zu noch besseren Ergebnissen führen.
Wie sieht es mit dem Datenschutz aus?
Wie wirkt sich der Datenschutz auf die prädiktive Modellierung aus, nachdem der Zugang zu Daten auf Nutzerebene begrenzt ist?
Tatsache ist, dass Mobile Users in den letzten Jahren immer anspruchsvoller und kompetenter geworden sind. Da der Datenschutz im Mittelpunkt steht, muss der/die durchschnittliche App-Nutzer:in nicht mehr seine/ihre Daten zur Verfügung stellen, um eine App zu nutzen oder sogar um ein personalisiertes Erlebnis zu genießen.
Aber tappen die Werbetreibenden wirklich im Dunkeln, wenn es um den Zugang zu Qualitätsdaten geht?
Die kurze Antwort lautet: nicht unbedingt. Mit der Kombination von prädiktiver Modellierung,SKAdNetwork, aggregierten Daten und Kohortenanalyse können Marketers selbst in einer IDFA-begrenzten Realität fundierte Entscheidungen treffen.
Aber wo soll man beginnen? Es ist eine Sache, Events zu messen, die Performance zu beobachten und zu optimieren. Eine ganz andere Sache ist es, eine riesige Datenmenge zu analysieren und Prognosemodelle zu entwickeln und einzusetzen, die es Ihnen ermöglichen, flexible und präzise datengesteuerte Entscheidungen zu treffen.
Machen Sie sich keine Sorgen. Wir sind hier, um Ihnen zu helfen, alles zu verstehen.
In diesem praktischen Guide – einer Zusammenarbeit zwischen AppsFlyer, der digitalen Marketing-Agentur AppAgent und Incipia – erforschen wir, wie Marketers ihr Datenwissen auf die nächste Stufe heben und sich mit Hilfe von prädiktiven Modellen den begehrten Wettbewerbsvorteil verschaffen können.

Warum sollte man überhaupt prädiktive Modelle erstellen?
Prädiktive Modellierung bietet zahlreiche Vorteile für das Mobile Marketing, aber wir haben uns auf zwei wichtige Marketingaktivitäten konzentriert:
1. Nutzerakquise (UA)
Das typische Nutzerverhalten und die frühen Phasen zu kennen, die Nutzer:innen mit hohem Potenzial von solchen mit geringem Potenzial unterscheiden, kann sowohl bei der Akquise als auch beim Re-Engagement hilfreich sein.
Wenn ein:e Nutzer:in beispielsweise bis zum dritten Tag X Euro generieren sollte, um nach dem 30. Tag einen Gewinn zu erzielen, und diese Zahl unter Ihrer Benchmark liegt, wissen Sie, dass Sie Ihre Bids, Creatives, das Targeting oder andere Dinge anpassen müssen, um die Kosten/Qualität Ihrer akquirierten Nutzer:innen zu optimieren oder Ihre Monetarisierungstrends zu verbessern.
Liegt X jedoch über Ihrer Benchmark, können Sie getrost Ihre Budgets und Bids erhöhen, um einen noch größeren Nutzen aus Ihren gewonnenen Nutzern zu ziehen.
2. Datenschutzorientierte Werbung
Jahrelang bestand der größte Vorteil der Online-Werbung gegenüber der traditionellen Werbung darin, dass sie mit Hilfe großer Mengen messbarer Performance-Daten die gewünschte Zielgruppe genau bestimmen konnte.
Je spezifischer Ihre Kampagnen sind, desto wahrscheinlicher ist es, dass Sie einen höheren LTV der Nutzer:innen und eine effiziente Budgetierung erreichen. Aber was wäre, wenn Sie die Tore zu einer größeren Stichprobengruppe öffnen und einen unmittelbaren Einblick in deren potenziellen Wert gewinnen könnten?
Mit der prädiktiven Modellierung können Sie genau das tun: Die potenzielle Zielgruppe Ihrer Kampagne erweitern. Indem Sie verschiedene Cluster von Verhaltensmerkmalen erstellen, können Sie Ihre Zielgruppe nicht nach ihrer Identität segmentieren, sondern nach ihrer Interaktion mit Ihrer Kampagne in ihrer frühesten Phase.
Was soll ich messen?
Um zu verstehen, was Sie messen müssen, damit Ihre Prognosen richtig sind, schauen wir uns an, welche Datenpunkte nützlich sind und welche nicht:
Metriken
Wie bei der Beziehung zwischen Quadrat und Rechteck: Alle Metriken sind Datenpunkte, aber nicht alle Metriken sind Key Performance Indicators (KPIs). Metriken sind einfacher zu berechnen und wesentlich effizienter als KPIs, die in der Regel komplexe Formeln beinhalten.
Beachten Sie, dass mit Apples SKAdNetwork die folgenden Metriken immer noch gemessen werden können, allerdings mit einem geringeren Genauigkeitsgrad. Mehr dazu im 5. Kapitel.
1) Ältere Metriken werden in der Regel mit geringem Vertrauen in die Gewinnprognose identifiziert, haben aber die schnellste Verfügbarkeit:
- Click to Install (CTI) – die direkte Conversion zwischen den beiden stärksten Touchpoints auf der Pre-Install User Journey. CTI ist sowohl sozial als auch technisch entscheidend, da niedrigere Raten auf eine nicht relevante Zielgruppe, ineffektive Creatives oder langsame Ladezeiten vor Abschluss der Installation hinweisen können.
Formel: Anzahl der Installationen / Anzahl der Ad-Clicks
- Click through Rate (CTR) – das Verhältnis zwischen einem Klick auf eine bestimmte Ad und der Gesamtzahl der Views. Im oberen Funnel hat die CTR nur einen begrenzten Wert für andere allgemeine Marketingziele, kann aber die Effektivität der Creative einer Kampagne anhand der erhaltenen Klicks direkt widerspiegeln.
Anzahl der Klicks / Anzahl der Ad-Views
Erforderliche Daten: Impressionen, Klicks, attribuierte Installationen
2) Frühindikatoren werden in der Regel mit mittlerem Vertrauen in die Gewinnprognose und schnelle Verfügbarkeit ermittelt.
Im Zeitalter des Down-Funnel-Fokus ist eine Installation kein ausreichender KPI mehr. Die folgenden Metriken sind zwar nicht für Gewinnprognosen geeignet, können aber dennoch als Frühindikatoren dienen, die den Marketers Aufschluss darüber geben, wie wahrscheinlich es ist, dass ihre Kampagnen einen Gewinn erzielen.
Beispiele hierfür sind:
- Cost per Install (CPI) – CPI konzentriert sich auf Paid Installationen und nicht auf organische Installationen und misst Ihre UA-Kosten als Reaktion auf Ad-Views.
Formel: Werbeausgaben / Gesamtzahl der Installationen, die direkt mit einer Werbekampagne verbunden sind
- Die Anzahl der wiederkehrenden Nutzer:innen nach einem bestimmten Zeitraum.
Berechnung: [(CE – CN) / CS)] X 100
CE = Anzahl der Nutzer am Ende des Zeitraums
CN = Anzahl der neuen Nutzer, die während des Zeitraums gewonnen wurden
CS = Anzahl der Nutzer zu Beginn des Zeitraums
Erforderliche Daten: Kosten, attribuierte Installationen, App-Öffnungen, (Retention Report)
Mit Ausnahme der Retention Rate sind Metriken eher an ein Marketingmodell als an Ihr Business-Modell gebunden und daher nicht geeignet, um festzustellen, ob die von Ihnen akquirierten Nutzer:innen Ihrem Unternehmen einen Gewinn bringen.
Wenn Sie 100 US-Dollar pro Klick oder pro Installation zahlen, ist es sehr wahrscheinlich, dass Sie keinen Gewinn machen werden. Wenn Ihre CTR bei 0,05 % liegt, ist es wahrscheinlich, dass die Auktionsmechanismen Sie zu einer hohen Rate pro Installation veranlassen, so dass Sie wiederum weniger Spielraum haben, um einen Gewinn zu erzielen.
Metriken unterstützen keine Prognosen, wenn Sie versuchen, Ihren Zuverlässigkeitsbereich genauer zu kalibrieren, z. B. wenn die Profitabilität innerhalb einer Spanne von 2 bis 6 US-Dollar CPI liegt.
KPIs
Es ist wichtig, die allgemeinen KPIs in zwei Bereiche zu unterteilen:
1) Tier-2-KPI-Prädiktoren mit hoher Zuverlässigkeit – definiert durch eine mittlere bis hohe Zuverlässigkeit bei der Gewinnprognose und geringe Verfügbarkeit:
Sie sind nützlich, um als frühe Benchmarks für den Gewinn zu dienen, und bieten mehr Vertrauen als Frühindikatoren (Metriken). Die Tier-2-KPIs brauchen mehr Zeit, um zu reifen, und bieten auch weniger Vertrauen als die Tier-1-KPIs.
*Beachten Sie, dass mit Apples SKAdNetwork die folgenden KPIs nicht zusammen gemessen werden können.
- Kundenakquisitionskosten pro zahlende:m Nutzer:in
- Kosten oder Conversion von Kernaktionen – z. B. Anteil der am ersten Tag gespielten Games oder Anteil der Inhaltsansicht während der ersten Session
- Zeitbasierte Kosten oder Conversion von Hauptaktionen – z. B. Kosten pro Anzahl der gespielten Games am ersten Tag oder Kosten pro Inhaltsansicht während der ersten Session
- Kosten pro Tag X für gebundene Nutzer:in: Gesamtausgaben pro Tag X Anzahl der an diesem Tag gebundenen Nutzer:innen.
- Vertikale spezifische In-App Events – z.B. Abschluss des Tutorials, Abschluss von Level 5 am ersten Tag (Gaming), Anzahl der aufgerufenen Produktseiten in der ersten Session, Anzahl der Sessions in 24 Stunden (Shopping), usw.
Erforderliche Datenpunkte: Kosten, attribuierte Installationen, App-Öffnungen (Retention Report), konfigurierte und gemessene In-App-Events, Session-Daten (Zeitstempel, genutzte Features usw.)
Für die meisten Business-Modelle können diese KPIs nicht als verlässliche Prädiktoren dienen, da sie zwar Kosten und Events berücksichtigen, die üblicherweise mit dem Gewinn korreliert sind, aber nicht die gesamte Monetarisierungsseite der Gewinngleichung berücksichtigen, da das Öffnen einer App nicht immer gleichbedeutend mit In-App-Ausgaben ist und zahlende Nutzer:innen möglicherweise mehr als einen Kauf tätigen.
2) Tier-1-KPIs, die mit hoher Wahrscheinlichkeit den Gewinn prognostizieren – frühe Umsätze und konsequente ROAS als Indikator für den langfristigen Erfolg – sind mit hoher Wahrscheinlichkeit für die Prognose des Gewinns, aber mit der langsamsten Verfügbarkeit gekennzeichnet:
Tier-1-KPIs brauchen entweder länger, bis sie vollständig ausgereift sind, oder ihre Ermittlung erfordert komplexe Prozesse. Sie stehen jedoch in direktem Zusammenhang mit Ihrem Business-Modell und sind daher perfekt geeignet, um die Profitabilität Ihrer Marketingkampagnen zu prognostizieren.
- Return on Ad Spend (ROAS) – Die Ausgaben für Marketing dividiert durch die von den Nutzern in einem bestimmten Zeitraum erzielten Umsätze.
Lifetime Value (LTV) – Die Höhe des Umsatzes, die Nutzer:innen bisher mit Ihrer App generiert haben.
Formel: Durchschnittlicher Wert einer Conversion x Durchschnittliche Anzahl von Conversions in einem Zeitrahmen x Durchschnittliche Customer Lifetime
Erforderliche Datenpunkte: Kosten, attribuierte Installationen, App-Öffnungen, detailliertes Umsatz-Measurement (IAP, IAA, Abonnement, usw.)
ROAS ist zwar einfacher zu berechnen, aber es dauert Wochen oder sogar Monate, bis die Nutzer:innen weiterhin einen Umsatz generieren. In Kombination mit dem durchschnittlichen Umsatz pro Nutzer:in kann der LTV eine gute Möglichkeit sein, den voraussichtlichen Gesamtumsatz oder Wert Ihrer App zu ermitteln.
Zusammenfassend lässt sich sagen, dass die einzelnen Strategien in der folgenden Tabelle aufgeführt sind:


Die Erstellung eines LTV-Modells zur Prognose des ROAS könnte angesichts der Komplexität und der zahlreichen Prognosekonzepte, die es gibt, überwältigend sein.
Es gibt offensichtliche Unterschiede wie Apps die Nutzer:innen binden und monetarisieren, geschweige denn wie unterschiedlich In-App-Käufe bei Games, abonnementbasierte Apps und E-Commerce-Businesses sind.
Es ist eindeutig, dass es kein einheitliches LTV-Modell für alle geben kann.
Um die komplexen Zusammenhänge besser zu verstehen, haben wir mit einer Reihe von Experten aus Gaming- und Nicht-Gaming-Unternehmen gesprochen, unter anderem mit Hutch Games,Wargaming, Pixel Federationund Wolt.
Hier sind die wichtigsten Fragen, die wir behandelt haben:
- Welche LTV-Modelle nutzen Sie?
- Wie hat sich Ihr LTV-Modell im Laufe der Zeit bewährt?
- Wie ist die Zuständigkeit für die prädiktive Modellierung im Unternehmen geregelt?
- Was ist Ihre ultimative Metrik für die Nutzerakquise?
- Wie stehen Sie zur UA-Automatisierung und zu zukünftigen Trends?
LTV-Modelle
Aus unseren Gesprächen geht hervor, dass es bei den LTV-Prognosen drei Denkweisen gibt:
1) Retention-getriebenes / ARPDAU-Retention-Modelle
- Konzept: Erstellen Sie eine Retentionskurve auf der Grundlage einiger anfänglicher Retentionsdaten, berechnen Sie dann die durchschnittliche Anzahl aktiver Tage pro Nutzer:in (für Tag 90, 180 usw.) und multiplizieren Sie diese mit dem durchschnittlichen Umsatz pro täglichem aktiven Nutzer:innen (ARPDAU), um den prognostizierten LTV zu erhalten.
- Beispiel: Die Retention am T1 / T3 / T7 beträgt 50 % / 35 % / 25 %. Nach der Anpassung dieser Daten und der Berechnung ihres Integrals bis T90 ergibt sich, dass die durchschnittliche Anzahl der aktiven Tage 5 beträgt. Wenn man weiß, dass der ARPDAU 40 Cent beträgt, würde der prognostizierte T90 LTV 2 US-Dollar entsprechen.
- Guter Bezug: Apps mit hoher Retention (Games wie MMX Racing). Einfach einzurichten, kann vor allem dann nützlich sein, wenn nicht genügend Daten für andere Modelle vorhanden sind.
- Schlechter Bezug: Apps mit geringer Retention (z. B. E-Commerce), die nicht auf eine ausreichende Anzahl von Retentionsdaten zugreifen können, um dieses Modell aufrechtzuerhalten.
2) Ratio-gesteuert
- Berechnung: Berechnen Sie einen Koeffizienten (T90 LTV / T3 LTV) aus historischen Daten und dann für jede Kohorte und wenden Sie diesen Koeffizienten an, um den tatsächlichen T3 LTV zu multiplizieren, um eine T90 LTV-Prognose zu erhalten.
- Beispiel: Nach den ersten 3 Tagen liegt der ARPU für unsere Kohorte bei 20 Cent. Anhand historischer Daten wissen wir, dass T90/T3 = 3 ist. Der prognostizierte T90 LTV würde daher 60 Cent (20 Cent ARPU*3) betragen.
- Falls es nicht genügend historische Daten gibt, um ein zuverlässiges Verhältnis zu berechnen (d.h. wir haben nur Daten für 50 Tage und wollen eine Prognose für den T180 LTV, oder wir haben zu wenige Stichproben für den T180 LTV), kann eine erste Schätzung anhand der vorhandenen Datenpunkte vorgenommen und dann kontinuierlich verfeinert werden, wenn mehr Daten vorliegen.
Aber in diesen Fällen ist es notwendig, solche Schätzungen mit Vorsicht zu betrachten.
- Guter Bezug: „Standard“-Apps, einschließlich vieler Gaming-Genres oder E-Commerce-Apps.
- Schlechter Bezug: Abonnementbasierte Apps mit einer Woche kostenloser Testversion. Es kann viel Zeit vergehen, bis ein Kauf stattfinden kann, und da diese Methode kaufbasiert ist, wäre eine Prognose fast unmöglich.
3) Verhaltensgesteuerte Prognosen
- Berechnung: Die Erfassung einer beträchtlichen Menge an Daten von zustimmenden App-Nutzern (Session- und Engagementdaten, Käufe, In-App-Nachrichten usw.) und deren Verarbeitung mit Hilfe von Regressionen und maschinellem Lernen, um zu definieren, welche Aktionen oder Aktionskombinationen die besten „Prädiktoren“ für den Wert eines neuen Nutzers sind.
Ein Algorithmus weist dann jeder:m neuen Nutzer:in einen Wert zu, der auf einer Kombination von Merkmalen (z. B. Plattform oder UA-Kanal) und durchgeführten Aktionen (oft während einiger anfänglicher Sessions oder Tage) basiert.
Es ist wichtig zu erwähnen, dass seit der Einführung von Apples datenschutzorientierten Einschränkungen mit iOS 14 keine Prognosen auf Nutzerebene mehr möglich sind. Davon abgesehen sind aggregierte Nutzerprognosen noch möglich.
- Beispiel: Nutzer:in A hatte 7 lange Sessions an Tag 0 und insgesamt 28 Sessions bis Tag 3. Sie besuchten auch die Tarife-Seite und blieben dort über 60 Sekunden lang.
Laut der Regressionsanalyse und dem auf maschinellem Lernen basierenden Algorithmus liegt die Wahrscheinlichkeit, dass sie in Zukunft einen Kauf tätigen, bei 65 %. Bei einem ARPPU von 100 US-Dollar liegt ihr voraussichtlicher LTV daher bei 65 US-Dollar.
- Guter Bezug: Jede App mit Zugang zu einem erfahrenen Data-Science-Team, technischen Ressourcen und vielen Daten. In manchen Fällen könnte dies eine der wenigen praktikablen Optionen sein (z. B. Abonnement-Apps mit einer langen kostenlosen Testversion).
- Schlechter Bezug: Für viele kleine und mittelgroße Apps könnte das ein Overkill sein. In den meisten Fällen können weitaus einfachere Ansätze zu ähnlichen Ergebnissen führen, sind viel einfacher zu pflegen und werden vom Rest des Teams verstanden.
Auswahl des richtigen Modells für verschiedene App-Typen
Jede App und jedes Team haben ihre eigene Mischung aus Parametern und Gesichtspunkten, die in den Auswahlprozess einfließen sollten:
- Auf der Produktseite ist es eine einzigartige Kombination aus App-Typ und -Kategorie, Monetarisierungsmodell, Kaufverhalten der Nutzer:innen und verfügbaren Daten (und deren Varianz).
- Auf der Seite des Teams geht es um die Kapazität, die technischen Fähigkeiten, das Wissen und die verfügbare Zeit, bevor das UA-Team das Betriebsmodell benötigt.
In diesem Abschnitt werden wir einige vereinfachte Beispiele für den Auswahlprozess darstellen.
Diese basieren auf echten Fällen von drei verschiedene Apps: ein Free-to-Play-Game (F2P), eine App auf Abonnementbasis und eine E-Commerce-App.

Abonnementbasierte Apps
Im Folgenden werden zwei Fälle von abonnementbasierten Apps behandelt, die jeweils eine andere Art von Paywall aufweisen – ein Hard Gate und eine zeitlich begrenzte kostenlose Testversion:
1. Die harte Paywall: Ein kostenpflichtiges Abonnement beginnt oft am Tag 0 (z. B. 8fit).
Gute Neuigkeiten: Wir haben bereits nach dem ersten Tag eine sehr genaue Angabe über die Gesamtzahl der Abonnenten (z. B. nehmen wir an, dass 80 % aller Abonnenten dies am Tag 0 tun werden, und die restlichen 20 % irgendwann in der Zukunft).
Unter der Voraussetzung, dass wir unsere Abwanderungsraten und folglich unseren ARPPU bereits kennen, können wir den LTV der Kohorten leicht vorhersagen, indem wir einfach die Multiplikation von (Anzahl der Zahler:innen)*(ARPPU für ein bestimmtes Nutzersegment)*(1,25 als Koeffizient, der die zusätzlichen geschätzten 20 % der Nutzer:innen repräsentiert, von denen erwartet wird, dass sie in Zukunft kaufen werden) durchführen.
2. Zeitlich begrenzte kostenlose Testversion: In diesem Fall wird ein Prozentsatz der Nutzer:innen nach Ablauf der Testversion in zahlende Abonnenten umgewandelt (z. B. Headspace). Das Problem ist, dass UA-Manager warten müssen, bis die Testversion vorbei ist, um die Conversion Rates zu verstehen.
Diese Verzögerung kann besonders beim Testen neuer Kanäle und GEOs problematisch sein, weshalb Verhaltensprognosen hier nützlich sein könnten.
Selbst bei einem moderaten Datenvolumen und einfachen Regressionen ist es oft möglich, gute Prädiktoren zu identifizieren. Wir könnten beispielsweise herausfinden, dass Nutzer:innen, die an der kostenlosen Testversion teilnehmen und in den ersten drei Tagen nach der Installation mindestens drei Sessions pro Tag absolvieren, in 75 % der Fälle zu einem Abonnement wechseln.
Obwohl der obige Prädiktor bei weitem nicht perfekt ist, könnte er für die Entscheidungsfindung in der UA präzise genug sein und dem UA-Team eine gute Handlungsfähigkeit bieten, bevor weitere Daten aufgenommen werden und ein geeignetes Modell getestet wird.
Die Art und Gestaltung von Paywalls kann stark von der Notwendigkeit beeinflusst werden, den Traffic schnell zu bewerten.
Sie sollten so schnell wie möglich herausfinden, ob Nutzer:innen konvertieren (oder nicht), um die Rentabilität der Kampagne zu verstehen und schnell reagieren zu können. Wir haben festgestellt, dass dies für mehrere Unternehmen einer der entscheidenden Faktoren bei der Entscheidung für eine Art von Paywall ist.
Freemium Games
Free-to-Play (F2P) -Games haben in der Regel eine hohe Retentionsrate und eine hohe Anzahl von Käufen.
1) Gasual Game (Diggy’s Adventure):
Für In-App-Käufe eignet sich das „Ratio-Modell“, bei dem es möglich sein sollte, den T(x)LTV nach drei Tagen ziemlich sicher vorherzusagen, da wir bis dahin die meisten unserer zahlenden Nutzer:innen bereits identifiziert haben sollten.
Für einige Games, die sich über Werbung finanzieren, könnte auch der Ansatz der Retention in Betracht gezogen werden.
2) Hardcore Game (World of Tanks oder MMX Racing):
Die ARPPU-Verteilung bei Hardcore-Nutzer:innen kann erheblich verzerrt sein, wenn die Nutzer:innen mit den höchsten Ausgaben – auch „Wale“ genannt – das X-Fache der anderen ausgeben können.
Das „Ratio-Modell“ könnte in diesen Fällen immer noch funktionieren, sollte aber verbessert werden, um die unterschiedlichen Ausgaben-Niveaus der verschiedenen Ausgabentypen zu berücksichtigen. Hier würde eine „Nutzertyp“-Variable den Nutzern unterschiedliche LTV-Werte zuweisen, die auf ihrem Ausgabeverhalten basieren (d. h. wie viel sie ausgegeben haben, wie viele Käufe sie getätigt haben, welches Starterpaket sie gekauft haben usw.).
Je nach den Daten könnte eine erste Prognose nach dem dritten Tag erstellt werden und ein weiterer etwas später (am fünften oder siebten Tag), nachdem die Ausgaben der Nutzer:innen ermittelt wurden.
E-Commerce-Apps
E-Commerce-Apps haben in der Regel ein einzigartiges Retentionsverhalten, da ihr Start oft an eine bestehende Kaufabsicht gebunden ist, was nicht allzu oft vorkommt.
Daraus lässt sich schließen, dass die Methode des „bindungsbasierten Modells“ im Allgemeinen nicht gut für solche Apps geeignet ist. Lassen Sie uns stattdessen zwei alternative Anwendungsfälle genauer unter die Lupe nehmen:
1) Händler für Flugtickets
Die Zeit von der Installation bis zum Kauf für Reisen ist beträchtlich, manchmal Monate lang. Da sich Käufe und Umsätze über einen längeren Zeitraum erstrecken, werden die Modelle „Ratio“ oder „Retention“ in den meisten Fällen nicht funktionieren.
Daher sollten wir versuchen, in der ersten Session nach der Installation Verhaltenshinweise zu finden und potenzielle Prädiktoren aufzudecken, da dies oft die einzigen Informationen sind, die uns zur Verfügung stehen.
Mit diesen Anhaltspunkten und unter der Voraussetzung, dass genügend Daten vorhanden sind, schätzen wir die Wahrscheinlichkeit, dass ein:e Nutzer:in jemals ein Ticket kauft, und multiplizieren sie mit einem ARPPU für eine relevante Kombination seiner/ihrer Merkmale (Plattform, Herkunftsland usw.).
2) Online Marketplace
Die Nutzer:innen neigen dazu, kurz nach der Installation ihren ersten Kauf zu tätigen. Hinzu kommt, dass der Versand des ersten gekauften Artikels oft viel Zeit in Anspruch nimmt. Infolgedessen neigen die Kundinnen und Kunden dazu, die erste Lieferung abzuwarten, um den Service zu bewerten, bevor sie sich zu einem weiteren Kauf entscheiden.
Eine Prognose würde in diesem Fall keinen Sinn machen, da wir auf die Daten des „zweiten Kaufs“ zu lange warten und alle Berechnungen auf die ursprünglichen Daten beschränken.
Je nachdem, wann die Nutzer:innen ihre Bestellungen aufgeben (die meisten nehmen ihre Bestellungen in den ersten 5 Tagen auf), können wir die Ratio-Methode (T90/T5) anwenden und das Ergebnis mit einem anderen Koeffizienten multiplizieren, der die künftigen Käufe berücksichtigt.
Vom MVP bis zu komplexen Modellen
Alle Datenanalysten, mit denen wir bei großen Publishern gesprochen haben, waren sich einig, dass es wichtig ist, den Weg der Prognosen mit einem einfachen „Minimum Viable Product“ (MVP) zu beginnen.
Dabei geht es darum, die anfänglichen Hypothesen zu verifizieren, mehr über die Daten zu erfahren und schrittweise ein Modell aufzubauen. In der Regel bedeutet dies, dass nach und nach weitere Variablen hinzugefügt werden, um detailliertere und präzisere Modelle zu ermöglichen (z. B. K-Faktor, Saisonalität und Werbeumsatz, zusätzlich zur ursprünglichen Segmentierung nach Plattform, Land und UA-Kanal).
Komplex ist kein Synonym für „gut“. Die UA-Manager können schnell frustriert sein, wenn ihr Zugang zu Daten blockiert ist, weil jemand komplizierte Dinge tut.
Anna Yukhtenko, Data Analyst @Hutch Games
In der Praxis haben wir festgestellt, dass die Unternehmen dazu neigen, sich an konzeptionell einfache Modelle zu halten.
Dieses Ergebnis war überraschend. Wir gingen davon aus, dass die Datenteams, sobald sich das Produkt durchgesetzt hat, Algorithmen für maschinelles Lernen und KI einsetzen würden, um mit dem, was wir für einen Industriestandard hielten, gleichzuziehen. Wir haben uns geirrt. Zumindest teilweise.
Obwohl viele den Wert komplexer Modelle erkennen und diese in der Vergangenheit getestet haben, haben sich die meisten schließlich für einfachere Modelle entschieden. Dafür gibt es drei Hauptgründe:
1. Kosten-Nutzen-Verhältnis fortschrittlicher Modelle
Das Kosten-Nutzen-Verhältnis bei der Erstellung und Pflege eines komplexen Modells ergibt einfach nicht das richtige Verhältnis. Wenn mit einfacheren Modellen ein ausreichendes Maß an Vertrauen für den täglichen Betrieb erreicht werden kann, warum sollte man sich dann die Mühe machen?
2. Engineering-Zeit für die Erstellung/Wartung
Die Erstellung eines fortschrittlichen Modells kann viele Engineering-Stunden verschlingen, und noch mehr, um es zu verwalten, was für kleinere Teams ein großes Problem darstellt.
Oft hat die BI-Abteilung nur eine geringe Kapazität, dem Marketingteam zur Seite zu stehen, so dass die Marketers alleine einen ungleichen Kampf gegen Statistiken und Datenengineering bestreiten müssen.
3. Kontinuierliche Veränderungen
Jede Produktversion ist anders und wird anders monetarisiert (das Hinzufügen oder Entfernen von Features kann z. B. große Auswirkungen haben). Lokale Saisonalität und Auswirkungen auf den gesamten Markt sind zwei relevante Beispiele.
Änderungen müssen im Handumdrehen vorgenommen werden. Die Einführung von Änderungen an einem komplexen Modell kann ein mühsamer und langsamer Prozess sein, der sich in einem schnelllebigen Mobile-Umfeld mit kontinuierlichem Medieneinkauf als fatal erweisen kann.
Es ist viel einfacher, ein einfaches Modell zu optimieren, was oftmals von den Marketers selbst vorgenommen wird.
Für eine bestimmte App-Untergruppe könnte ein verhaltensbasiertes Modell die einzige Lösung sein. Während Unternehmen, die groß genug sind, um eine solche Investition zu tätigen, über ein erfahrenes Engineering- und Data-Science-Team verfügen sollten, entscheiden sich andere vielleicht für den Einsatz eines vorgefertigten Produkts, das ähnliche Qualitäten bietet.
Ein weiterer Datensatz, der zunehmend an Bedeutung gewinnt, sind werbegenerierte LTV-Modelle mit Schätzungen der Werbeumsätze auf Nutzerebene. Weitere Informationen zu diesem Thema finden Sie im 4. Kapitel.
Teams und Verantwortlichkeiten
Im Allgemeinen sollte die Entwicklung, Umsetzung und Anpassung eines prädiktiven LTV-Modells eine Aufgabe für ein Analytics/Data-Science-Team sein (sofern ein solches vorhanden ist).
Idealerweise kommen hier zwei Rollen ins Spiel: ein erfahrener Analyst mit einer großen Reichweite im Marketing, der auf strategischer und taktischer Ebene berät und entscheidet, welches Modell wie eingesetzt werden sollte. Und einen dedizierten Analysten, der tagtäglich für die LTV-Berechnungen und Prognosen zuständig ist.
Der „Tagesanalyst“ muss das Modell ständig überwachen und auf starke Schwankungen achten. Wenn beispielsweise die wöchentlich prognostizierten Umsätze nicht mit der Realität übereinstimmen und nicht innerhalb der vorgegebenen Grenzen liegen, kann eine Anpassung des Modells sofortvorgenommen werden, und nicht erst nach einigen Wochen oder Monaten.
„Teamwork kommt hier zum Vorschein. Wir haben eine Art Frühwarnsystem entwickelt, bei dem wir einmal im Monat zusammenkommen, alle Hypothesen, die in das Modell einfließen, durchgehen und dann überprüfen, ob sie noch zutreffen. Bislang haben wir etwa zwölf wichtige Hypothesen (z. B. den Wert des organischen Zuwachses, die Saisonalität usw.), die wir kontrollieren, um sicherzustellen, dass wir auf dem richtigen Weg sind.“
Tim Mannveille, Director of Growth & Insight @Hutch Games
Sobald die Prognoseergebnisse berechnet sind, werden sie automatisch an das UA-Team weitergeleitet und von diesem eingesetzt. UA-Manager verlassen sich meist einfach auf diese Ergebnisse und berichten über Diskrepanzen, aber sie sollten versuchen, die eingesetzten Modelle auf einer allgemeinen Ebene besser zu hinterfragen und zu bewerten (es ist nicht erforderlich, die Details hinter einem komplexen Modell und seinen Berechnungen zu verstehen).
Marketing-Profis, die für dieses Kapitel interviewt wurden:
- Fredrik Lucander von Wolt
- Andrey Evsa von Wargaming
- Matej Lancaric von Boombit (ehemals Pixel Federation)
- Anna Yukhtenko und Tim Mannveille von Hutch Games

Wenn Sie davon ausgehen, dass Sie mit Pivot-Tabellen, berechneten Feldern, bedingten Formatierungen und Lookups die Welt von Excel für Fortgeschrittene gemeistert haben, dann werden Sie vielleicht überrascht sein, dass Sie einen noch wichtigeren Trick aus dem Excel-Playbook verpassen.
Und nicht nur das: Mit diesem Trick lässt sich auch die Profitabilität Ihrer Mobile Marketing-Kampagnen prognostizieren!
Das folgende Kapitel ist ein kleiner Guide für die Erstellung eigener prädiktiver Modelle mit alltäglichen Tools.
Disclaimer: Berücksichtigen Sie, dass es sich hier um eine vereinfachte Variante eines prädiktiven Modells handelt. Um diese in großem Umfang einsetzen zu können, sind hochentwickelte Algorithmen für maschinelles Lernen erforderlich, die zahlreiche Faktoren berücksichtigen, die die Ergebnisse erheblich beeinflussen können. Wenn man nur einen Faktor betrachtet, um seinen Wert ( z.B. den Umsatz) zu prognostizieren, wird die Genauigkeit wahrscheinlich nicht ausreichen.
Mit Hilfe eines Streudiagramms und ein wenig Algebra können Sie eine Excel-Trendliniengleichung in ein wirksames Tool verwandeln, mit dem Sie z. B. frühzeitig den Punkt ermitteln können, an dem Ihre Marketingkampagnen nachweislich einen Gewinn erzielen werden.
Diese Methode kann Ihnen dabei helfen, von Vermutungen zu datengestützten Entscheidungen und zu einem besseren Vertrauen in die wöchentlichen Reportings zu gelangen.
Wie man einen 100%tigen ROAS nach 6 Monaten prognostiziert
Während der LTV, wenn er richtig durchgeführt wird, ein großartiger Prädiktor ist, ist der ROAS – insbesondere in der ersten Woche – aufgrund seiner breiten Zugänglichkeit eine weit verbreitete Metrik zur Gewinnmessung.
Insbesondere werden wir den ROAS der Woche 0 (Umsatz in der ersten Woche der Nutzerakquise/Kosten für die Nutzerakquise) als zuverlässigen Prädiktor nutzen, der eine kohortenbasierte Methode zum Benchmarking der wöchentlichen Performance der Ads darstellt.
Mit dem ROAS der Woche 0 können wir vorhersagen, ob wir nach 6 Monaten den Break-even unserer Werbeausgaben mit 100 % ROAS erreichen.
Schritt 1
Der erste Schritt zur Nutzung von Excel für die Gewinnprognose besteht darin, sicherzustellen, dass Sie genügend Daten für Woche 0 und 6 Monate haben. Während Sie technisch gesehen eine Steigung zeichnen und eine Prognose für jeden Punkt auf dieser Steigung mit zwei Datenpunkten treffen können, wird Ihre Prognose alles andere als solide sein, wenn Sie nur wenige Daten hinzufügen.
Die ideale Anzahl der Messungen hängt von einer Vielzahl von Faktoren ab, wie z. B. dem gewünschten Konfidenzniveau, Korrelationen im Datensatz und zeitlichen Beschränkungen. Als Faustregel für ROAS-basierte Prognosen für Woche 0 sollten Sie jedoch mindestens 60 Paare von ROAS-Messungen für Woche 0 und 6 Monate anstreben.
Es ist auch wichtig, genügend Daten zu erfassen, die das von Ihnen festgelegte Zielniveau erreicht haben. Wenn Sie 60 Datenpunkte haben, aber nur 2 Punkte, an denen die 6-Monats-ROAS 100 % übersteigt, dann wird Ihr Gleichungsmodell nicht von einem ausreichenden Verständnis dafür getragen, welche Eingaben erforderlich sind, um diesen Break-even-Punkt zu erreichen.
Soweit Ihr Modell es beurteilen kann, könnte in diesem Fall die Voraussetzung, um nach 6 Monaten 100 % ROAS zu erreichen, entweder weitere 2 volle ROAS-Prozentpunkte oder 5 Prozentpunkte betragen, was eine sehr große Spanne ist, die sich nicht gut vorhersagen lässt.
Schritt 2
Sobald Sie genügend Informationen für das Ziel gesammelt haben, besteht der zweite Schritt darin, Ihren Datensatz in zwei Gruppen aufzuteilen, eine für das Training und eine für die Prognose.
Legen Sie den Großteil der Daten (~80%) in die Trainingsgruppe. Zu einem späteren Zeitpunkt setzen Sie die Prognosegruppe ein, um die Genauigkeit Ihres Modells bei der Prognose der 6-Monats-ROAS anhand der ROAS der Woche 0 zu testen.
3. Schritt
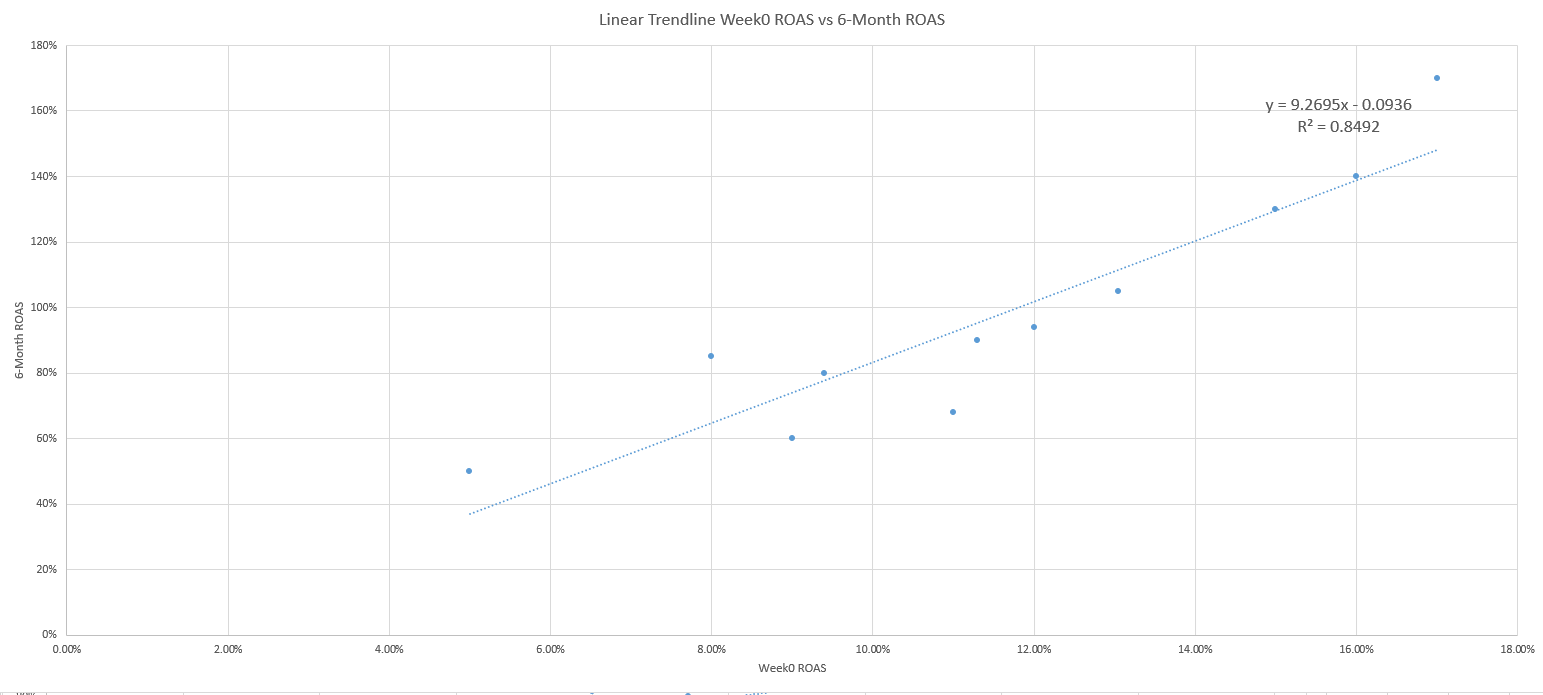
Der dritte Schritt besteht darin, die Daten in einem Streudiagramm darzustellen, wobei der ROAS der Woche 0 auf der x-Achse und der ROAS nach 6 Monaten auf der y-Achse liegt.
Fügen Sie dann eine Trendlinie hinzu und ergänzen Sie die Einstellungen für die Gleichung und das R-Quadrat.
Stellen Sie die Trainingsdaten mithilfe eines Streudiagramms grafisch dar.
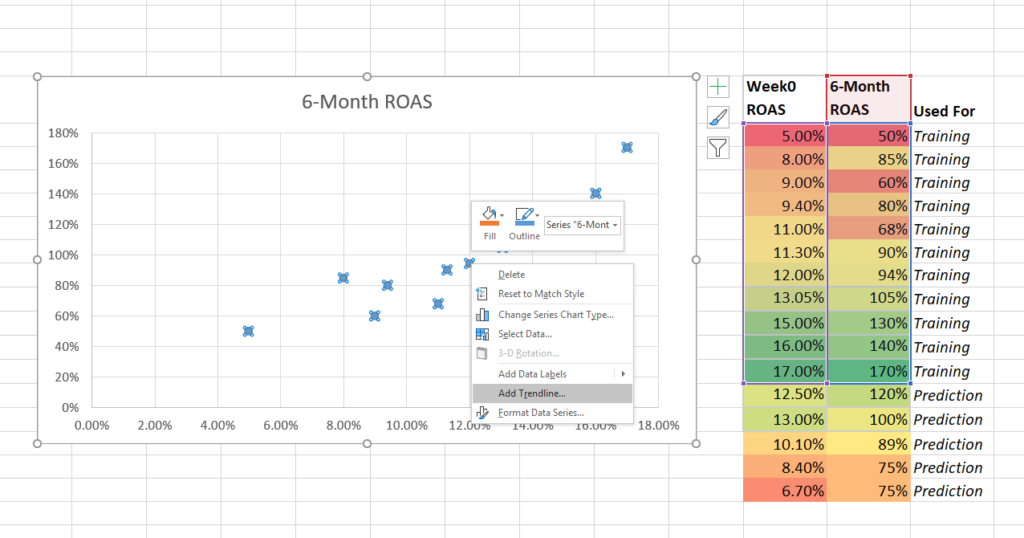
Klicken Sie mit der rechten Maustaste auf einen Datenpunkt und fügen Sie eine Trendlinie hinzu.
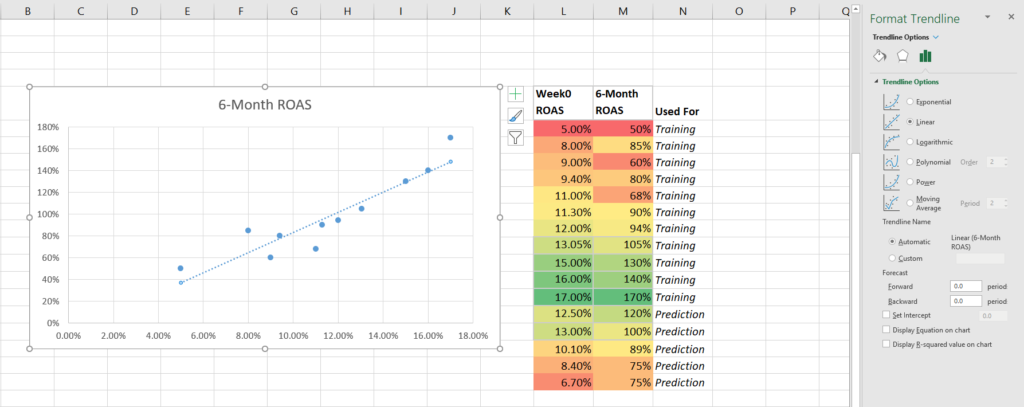
Addieren Sie die Trendliniengleichung und das R-Quadrat.
4. Schritt
In Schritt vier wird die lineare Gleichung y = mx + b benutzt, um den x-Wert der Gleichung (ROAS der Woche 0) zu lösen, wenn der y-Wert (ROAS nach 6 Monaten) 100 % beträgt.
Die Gleichung wird mit Hilfe der Algebra wie folgt umgestellt:
1. y = 9,2695x – 0,0936
2. 1 = 9,2695x – 0,0936
3. 1 + 0,0936 = 9,2695x
4. 1,0936 = 9,269x
5. X = 1,0936 / 9,269
6. X = 11,8 %
Auf diese Weise berechnen wir, dass die Antwort auf die Frage, wie man den Gewinn nach 6 Monaten vorhersagen kann, darin besteht, dass Ihr ROAS in der ersten Woche größer als 11,8 % sein muss.
Wenn Ihr ROAS der Woche 0 unter dieser Rate liegt, wissen Sie, dass Sie die Bids, Creatives oder Targeting anpassen müssen, um die Kosten/Qualität Ihrer akquirierten Nutzer:innen zu verbessern und Ihre Monetarisierungstrends zu verbessern.
Wenn Ihr ROAS in Woche 0 über dieser Zahl liegt, können Sie sicher sein, die Budgets und Bids zu erhöhen!
Schritt 5
Im fünften Schritt nutzen Sie Ihr Prognosesegment des vollständigen Datensatzes, um zu beurteilen, wie gut Ihr Modell die tatsächlichen Ergebnisse vorhersagen konnte. Dies kann anhand des Mean Absolute Percentage Error (MAPE) beurteilt werden, einer Berechnung, bei der der absolute Wert des Errors (tatsächlicher Wert minus vorhergesagter Wert) durch den tatsächlichen Wert geteilt wird.
Je niedriger die Summe des MAPE ist, desto besser ist die Prognosefähigkeit Ihres Modells.

Es gibt keine Faustregel für einen guten MAPE-Wert, aber im Allgemeinen gilt: Je mehr Daten Ihr Modell hat und je korrelierter die Daten sind, desto besser ist die Prognosefähigkeit Ihres Modells.
Wenn Ihr MAPE hoch ist und die Fehlerquoten inakzeptabel sind, kann es notwendig sein, ein komplexeres Modell zu nutzen. Modelle, die R und Python einbeziehen, sind zwar schwieriger zu verwalten, können aber die Prognosefähigkeit Ihrer Analyse erhöhen.
Zusammengefasst: Ein Konzept für die Prognose der Rentabilität von Marketingkampagnen.
Aber hören Sie noch nicht auf zu lesen! Dieser Guide hat noch viel mehr zu bieten.
Verbessern Sie Ihre Prognosen
Für die neugierigen Leser da draußen stellt sich vielleicht die Frage, ob die standardmäßige, lineare Trendlinie für die Gewinnprognose am besten geeignet ist.
Vielleicht probieren Sie sogar noch ein paar weitere Trendlinien aus und stellen fest, dass sich das R-Quadrat (ein Maß für die Anpassung der Gleichung an Ihre Daten) bei anderen Gleichungen verbessert, was diese Frage noch interessanter macht.
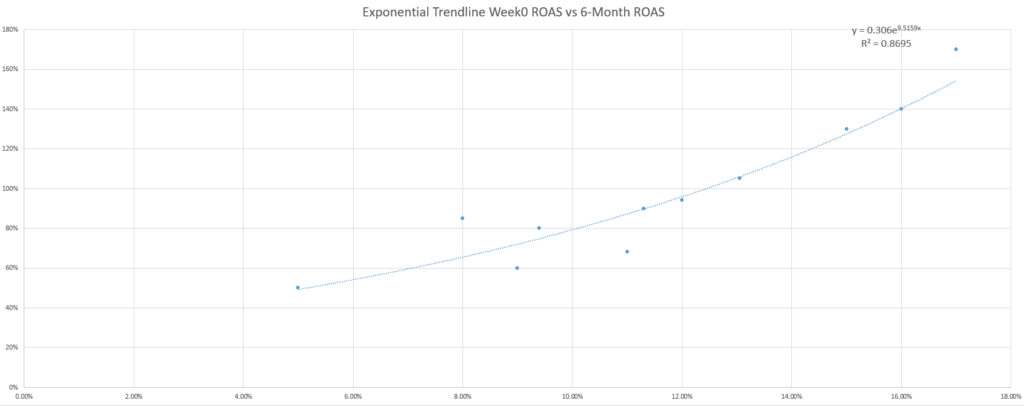
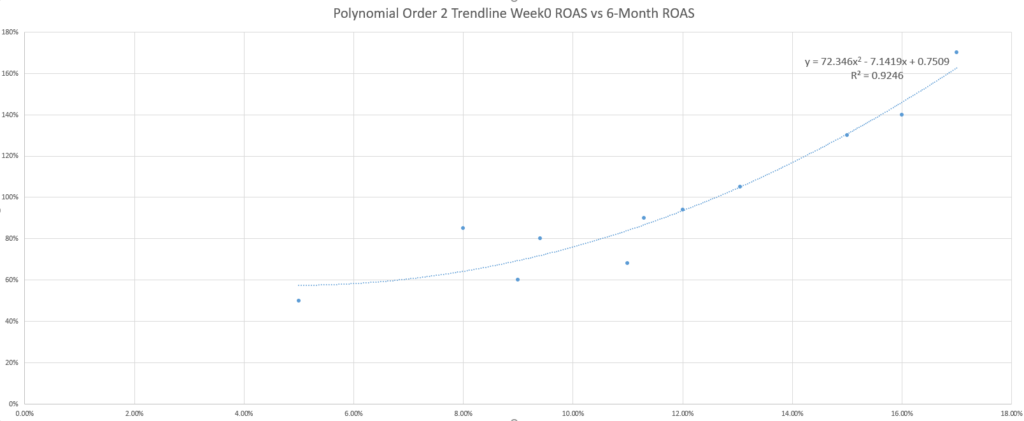
Während das Marketing-Sprichwort „Es kommt darauf an“ auch bei der Auswahl der besten Trendlinie gilt, ist ein anderes Marketing-Sprichwort als Antwort nützlich: KISS (Keep It Simple, Dummkopf). Wenn Sie kein Statistiker oder Mathefanatiker sind, sollten Sie am besten die einfacheren Trendlinien nutzen, d. h. die linearen.
Warum ist das ein Problem? Als einfaches Beispiel könnte man das Hinzufügen von unerwarteten Daten in das Modell erwägen. In den folgenden beiden Szenarien sehen Sie, wie sich eine niedrigere ROAS der Woche 0, die sich unerwartet gut entwickelt, oder eine höhere ROAS der Woche 0, die sich unerwartet schlecht entwickelt, auf die Genauigkeit der einzelnen Trendlinienmodelle auswirkt (bewertet anhand des MAPE).

Die Nutzung des MAPE zum Vergleich der verschiedenen trendlinienbasierten Modelle zeigt, dass die linearen und exponentiellen Modelle zwar nicht in jedem Fall die genauesten, aber die konsistentesten sind.
Darüber hinaus kann maschinelles Lernen Ihnen die Möglichkeit geben, diesen Prozess zu automatisieren, größere Datenmengen zu analysieren und schnellere Erkenntnisse zu gewinnen.
Stellen Sie sicher, dass Sie den richtigen Weg gehen
Abschließend sollten Sie sich diese Liste zusätzlicher Fragen ansehen, die hilfreich sein können, um sicherzustellen, dass Ihre Prognoseanalyse auf einem soliden Fundament aufgebaut ist:
- Haben Sie Ihr Modell kontinuierlich mit den wichtigsten Daten aktualisiert, um es zu trainieren?
- Haben Sie geprüft, ob die Prognosen Ihres Modells auf der Grundlage neuer Beobachtungen zutreffen oder nahe daran liegen?
- Gibt es zu viele Variationen oder umgekehrt eine Überausstattung?
- Ein sehr niedriges R-Quadrat oder ein sehr hohes R-Quadrat deuten auf ein Problem bei der Fähigkeit Ihres Modells hin, neue Daten akkurat vorherzusagen.
- Haben Sie den richtigen KPI genutzt?
- Testen Sie verschiedene KPIs (z. B. mehr oder weniger ROAS- oder LTV-Tage) und vergleichen Sie anhand des MAPE die Profitabilität der einzelnen KPIs.
Sie werden überrascht sein, wie schlecht die Standardmaße korreliert sind.
- Haben sich Ihre Frühindikatoren oder ersten Benchmarks signifikant verändert?
- Dies kann ein Anzeichen dafür sein, dass sich in der Praxis etwas Wesentliches geändert hat und dass sich für die Fähigkeit Ihres Modells, den Profit in Zukunft genau vorherzusagen, Probleme anbahnen.
- Haben Sie die Daten segmentiert?
- Die Segmentierung der Nutzer in homogenere Gruppen ist eine gute Möglichkeit, Störungen zu reduzieren und die Prognose Ihres Modells zu verbessern.
Wenden Sie beispielsweise nicht dasselbe Modell auf alle Nutzer:innen in allen Kanälen und Regionen an, wenn diese Nutzer:innen deutlich unterschiedliche Retentions- und Kostentrends aufweisen.
- Berücksichtigen Sie die zeitlichen Einflüsse?
- Die meisten Marketer sind sich des Einflusses der Saisonalität bewusst, die Prognosen beeinträchtigen kann. Aber auch der Lebenszyklus Ihrer App/Kampagne/Zielgruppe/Creative kann die Fähigkeit Ihres Modells, genaue Prognosen zu erstellen, beeinflussen.

In-App-Advertising (IAA) wird immer beliebter und hat in den letzten Jahren mindestens 30 % der App-Umsätze ausgemacht. Hyper-Casual- und Casual-Games sowie viele Utility-Apps nutzen diese Umsatzquelle natürlich als Hauptquelle für ihre Monetarisierung.
Sogar Developer, die bisher vollständig auf In-App-Käufe (IAP) angewiesen waren, sind dazu übergegangen, mit Werbung zu monetarisieren. Das Ergebnis ist, dass viele Apps nun erfolgreich beide Umsatzquellen kombinieren, um den LTV ihrer Nutzer:innen zu maximieren.
Ein Beispiel dafür ist Candy Crush von King.
Der LTV der hybriden Monetarisierung setzt sich aus zwei Teilen zusammen:
- In-App-Käufe/Abonnement-LTV: Umsätze, die aktiv von einem:r Nutzer:in generiert werden, der/die In-Game- oder In-App-Währung, besondere Gegenstände, zusätzliche Dienste oder ein kostenpflichtiges Abonnement kauft.
- In-App-Werbung LTV Umsätze, die passiv von einem:r Nutzer:in generiert werden, der/die sich Werbung ansieht und/oder mit ihr interagiert (Banner, Videos, Interstitials usw.)
Die Daten-Herausforderung
Idealerweise sollten Marketers in der Lage sein, den nominalen Wert jeder einzelnen Impression zu verstehen – was praktisch zu einem „Kauf“ führen würde. Wenn wir genügend Daten gesammelt haben, können wir Prognosemodelle erstellen, ähnlich denen, die wir bereits im zweiten Kapitel für In-App-Käufe beschrieben haben.
In der Realität ist das jedoch nicht so einfach – selbst die Berechnung des LTV von In-App-Ads ist aufgrund des Umfangs und der Struktur der Umsatzdaten, auf die Marketers zugreifen können, schwierig.
Hier sind nur einige Beispiele:
- Es gibt nur selten eine einzige Ad-Quelle, die angezeigt wird. In Wirklichkeit gibt es viele, viele Quellen, hinter denen ein Algorithmus/Tool steht (Ad-Mediation-Plattformen), die ständig Quellen und eCPM wechseln.
- Wenn ein:e Nutzer:in zehn Ads ansieht, ist es durchaus möglich, dass diese von fünf verschiedenen Quellen stammen, die jeweils einen völlig unterschiedlichen eCPM haben.
- Einige Werbenetzwerke zahlen für Aktionen (Installation, Klick) und nicht für Impressionen, was das Ganze noch weiter verkompliziert.
- Wenn Sie mit gängigen Mediationsplattformen arbeiten, die Werbeumsätze auf Nutzerebene anbieten, bleiben die Zahlen eine Schätzung. Die entsprechenden Werbenetzwerke geben diese Daten oft nicht weiter, was in der Regel zu einer Aufteilung der erzielten Umsätze auf die Nutzer:innen führt, die die Impressionen gesehen haben.)
- Die eCPMs können im Laufe der Zeit drastisch schwanken, und es ist unmöglich, diese Veränderungen zu prognostizieren.
LTV-Prognosemodelle für In-App-Ads
Viele der von uns befragten Unternehmen befassen sich nicht wirklich mit LTV-Prognosen für Ads. Unter den Marketern von Gaming-Apps, die sich für das Thema interessierten, war sich niemand sicher, wo sie beginnen sollten. Stattdessen war es eher ein nebenstehendes Projekt.
Im Folgenden werden die Konzepte weiter erläutert:
1. Das retention-basierte/ARPDAU-Retention-Modell
- Berechnung: Mit dem ARPDAU-Retention-Modell, das in diesem Fall auch den zusätzlichen Beitrag von In-App-Werbeumsatze, enthält.
- Beispiel: Die Retention von T1/T3/T7 beträgt 50 %/35 %/25 %. Nach der Anpassung dieser Datenpunkte an eine Power-Kurve und der Berechnung ihres Integrals bis D90 ergibt sich, dass die durchschnittliche Anzahl der aktiven Tage 5 beträgt. Wenn man weiß, dass der ARPDAU 50 Cent beträgt, würde der prognostizierte T90-LTV daher 2,50 $ betragen.
2. Die ratio-basierte Methode
- Berechnung: Die Einbeziehung von Schätzungen der Werbeumsätze auf Nutzerebene werden in die Berechnung aufgenommen, um die Ratio-Methode auf gleicher Weise zu nutzen (basierend auf den Koeffizienten von T1, T3, T7, etc.).
- Beispiel: Der aus In-App-Käufen und In-App-Werbeumsätzen berechnete ARPU liegt nach den ersten 3 Tagen bei 40 Cent. Wir wissen, dass T90/T7 = 3 ist. Der prognostizierte T90-LTV würde daher 1,20 $ betragen.
3. Die einfache Multiplikationsmethode
- Berechnung: Berechnung des Verhältnisses zwischen In-App-Käufen und Anzeigenumsätzen zur Ermittlung eines Multiplikators für die Berechnung des Gesamt-LTV. Wenn mehr Daten vorhanden sind, können mehrere Koeffizienten für Plattform-/Länderdimensionen berechnet werden, da diese in der Regel den größten Einfluss auf das Verhältnis zwischen Anzeigen- und In-App-Umsätzen haben.
Verknüpfung mit verhaltensbasierten LTV-Prognosen
Es ist wichtig, einen weiteren Schlüsselfaktor zu erwähnen, der die potenzielle Rentabilität von App-Nutzern stark beeinflussen kann: die Kannibalisierung.
Nutzer:innen, die Geld ausgeben, indem sie In-App-Käufe tätigen, haben oft einen deutlich höheren LTV als Nutzer:innen, die nur Werbung konsumieren. Es ist äußerst wichtig, dass ihre Absicht nicht durch Nachrichten über kostenlose praktische Dinge gestört wird.
Andererseits ist es wichtig, Anreize für die Nutzer:innen zu schaffen, damit sie sich die Werbung ansehen, daher werden sie oft mit In-App-Währung oder Boni belohnt.
Wenn eine App sowohl prämierte Werbung als auch In-App-Käufe enthält, ist es möglich, dass ein:e Spieler:in, der sonst IAP-Käufe tätigen würde, dies ab einem bestimmten Punkt nicht mehr tut, da er/sie im Gegenzug für das Ansehen von Werbung eine beträchtliche Prämie in Form von In-App-Währung erhält.
Genau hier kommen Verhaltensprognosen ins Spiel: Durch die Messung des Nutzerverhaltens kann ein Algorithmus für maschinelles Lernen die Wahrscheinlichkeit bestimmen, dass bestimmte Nutzer zu „Käufern“ werden, und aufzeigen, wo bestimmte Anpassungen des Spiels/der App erforderlich sind.
So funktioniert der Prozess:
- Alle Nutzer:innen sollten mit einem werbefreien Experience beginnen, während die Engagement-Daten gemessen werden.
- Der Algorithmus berechnet kontinuierlich die Wahrscheinlichkeit, dass ein:e Nutzer:in zur:m Käufer:in wird.
- Wenn diese Wahrscheinlichkeit über einem festgelegten Prozentsatz liegt, werden keine Ad mehr geschaltet, wenn mehr Daten gesammelt werden („Warten auf den Kauf“).
- Wenn die Wahrscheinlichkeit unter einen festgelegten Prozentsatz fällt, ist es sehr wahrscheinlich, dass diese:r Nutzer:in nie einen Kauf tätigen wird. In diesem Fall beginnt die App mit der Schaltung von Ads.
- Basierend auf dem längerfristigen Verhalten der Spieler kann der Algorithmus ihr Verhalten weiter auswerten und dabei die Anzahl der Ads und die Mischung der verschiedenen Formate ändern.
Die meisten Unternehmen geben sich mit einfachen Modellen und Ansätzen zufrieden, die ein optimales Kosten-Nutzen-Verhältnis bieten, insbesondere wenn es um Umsetzungsschwierigkeiten und den Mehrwert präziserer Insights geht.
In diesem Bereich sind bereits rasante Fortschritte zu beobachten, wobei verschiedene Lösungen auf den Markt kommen, um die Lücken zu schließen und das rasante Entwicklungstempo des Ökosystems sowie die wachsende Bedeutung der In-App-Werbung als wichtige Umsatzquelle für Apps zu ergänzen.
Die Beitragsmethode
Während gut abgestimmte Methoden zur Verhaltensprognose die genauesten Ergebnisse bei der Attribution von Werbeumsätzen liefern können, gibt es eine einfachere und praktikablere Methode, um das Problem der Attribution von Werbeumsätzen zu einer Akquisitionsquelle zu lösen.
Diese Methode basiert auf der Zuteilung des Anteils eines Kanals an den Werbeumsätzen anhand von aggregierten Datenpunkten zum Nutzerverhalten.
Die Deckungsbeiträge funktionieren, indem sie den Beitrag eines Kanals zum gesamten Nutzerverhalten in den Deckungsbeitrag dieses Kanals aus den von allen Nutzern generierten Werbeumsätzen umrechnen.
Theoretisch gilt: Je mehr Aktionen die akquirierten Nutzer:innen eines Kanals in einer App tätigen, desto einflussreicher und einträglicher ist dieser Kanal, wenn es darum geht, die Werbeumsätze mit diesen Nutzern zu verbuchen.
Um das zu verdeutlichen, nehmen wir das Ganze mal auseinander:
Schritt 1
Der erste Schritt besteht darin, einen Datenpunkt auszuwählen, der für die Ermittlung des Deckungsbeitrags der einzelnen Akquisitionsquellen genutzt wird.
Als Ausgangspunkt können Sie die Excel-Trendlinienregression nutzen, um herauszufinden, welcher KPI für das Nutzerverhalten am stärksten mit den Veränderungen bei den Werbeumsätzen korreliert.
Da bei der Contribution-Methode der Umsatz proportional zur Gesamtaktivität zugewiesen wird, sollten Sie einen Datenpunkt wählen, bei dem es sich um eine zählbare Anzahl aktiver Nutzer:innen pro Tag handelt, und nicht um eine verhältnismäßige Retentionsrate.
Einige Optionen sind:
- Gesamtzahl der aktiven Nutzer:innen
- Gesamtzahl der Sessions der Nutzer:innen
- Gesamtdauer der Session
- Attributionsdaten (z. B. Ad-Impressions)
- Gesamtzahl von Key Events (z. B. gespielte Games)
Schritt 2
Sobald Sie einige Datenpunkte zur Beobachtung haben, stellen Sie jeden Datenpunkt in einem Streudiagramm den gesamten Werbeumsätzen pro Tag gegenüber, um zu sehen, wo die Korrelationen zwischen Änderungen im Nutzerverhalten und den gesamten Werbeumsätzen am stärksten sind.
Schritt 3
Fügen Sie den R-Quadrat-Datenpunkt zu Ihrem Diagramm hinzu, um festzustellen, welcher Datenpunkt die stärkste Korrelation aufweist.
Diese Excel-Methode der Trendlinienregression hat einen Nachteil: Je geringer die Schwankungen im Nutzerverhalten und bei den Werbeumsätzen sind, desto ungenauer ist die Fähigkeit des Modells, die Stärke der Korrelation zwischen den Datenpunkten zu erkennen.
Infolgedessen werden Sie kaum in der Lage sein, einen Datenpunkt einem anderen vorzuziehen.
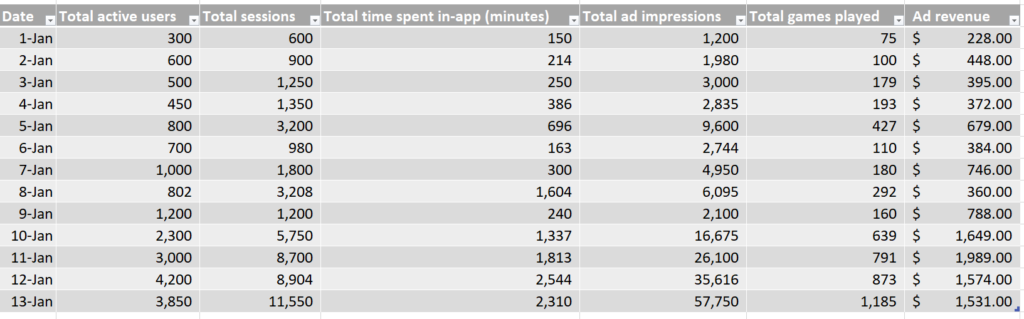
In diesem simulierten Datensatz sehen wir die tägliche Anzahl der einzelnen Datenpunkte sowie die gesamten täglichen Werbeumsätze.
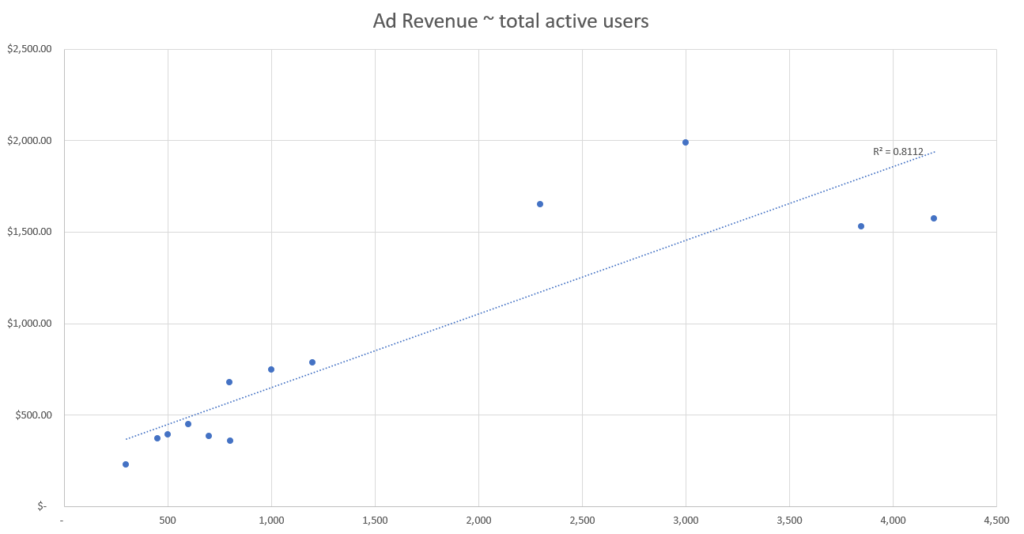
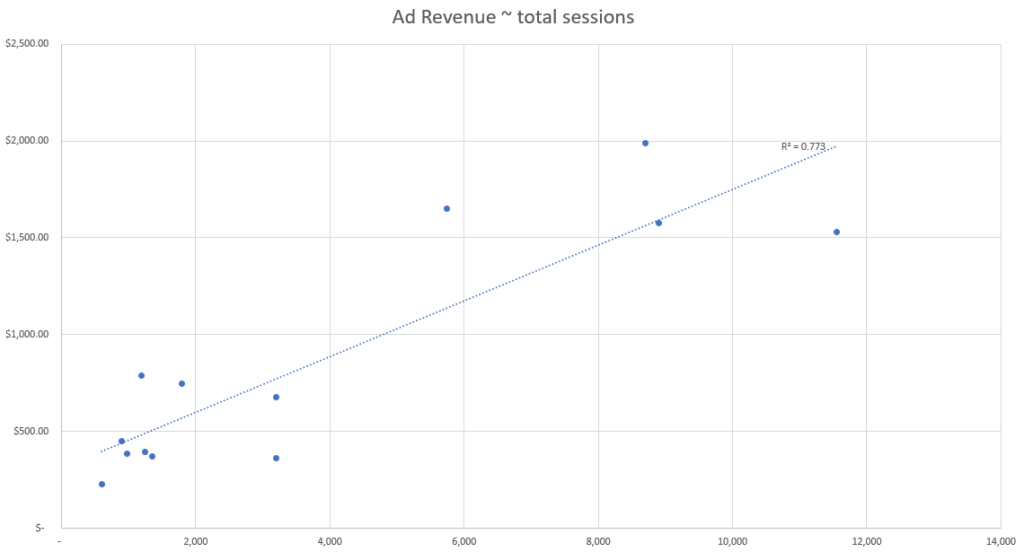
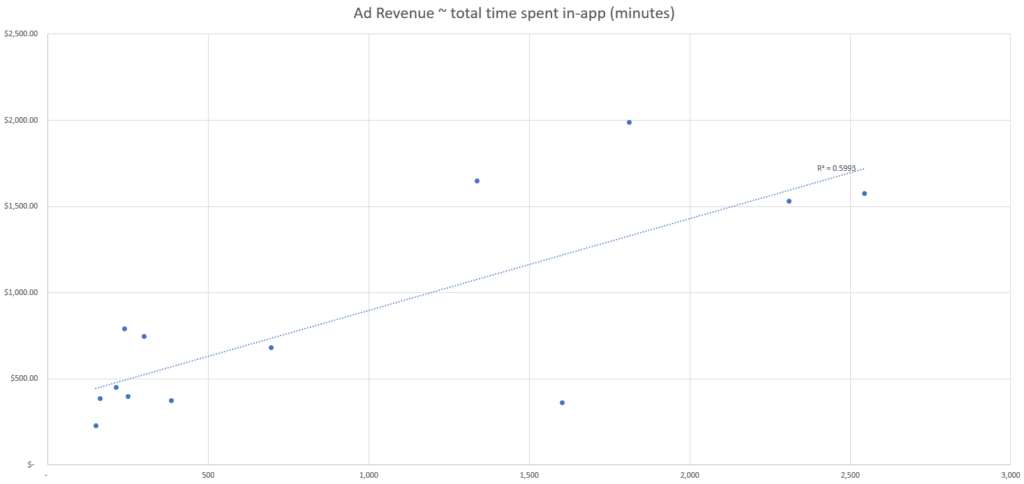
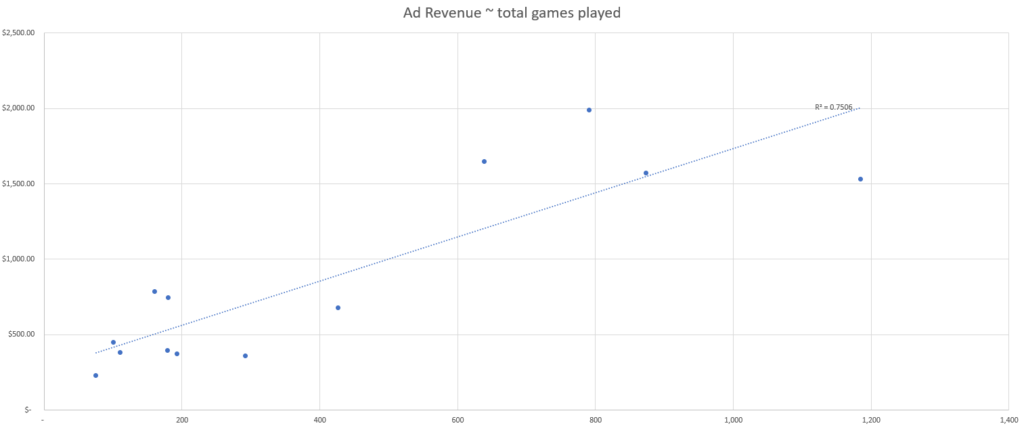
Anhand dieser simulierten Daten können wir erkennen, dass das Event mit der besten Korrelationsstärke die Anzahl der aktiven Nutzer:innen sind, basierend auf unserer R-Quadrat-Fit-Metrik.
Das bedeutet, dass der Datenpunkt aus unserem Set, der die Veränderungen bei den Werbeumsätzen am besten erklärt, die Anzahl der aktiven Nutzer:innen ist, und wir daher die Anzahl der aktiven Nutzer:innen nutzen sollten, um die Werbeumsätze nach Kanal zuzuordnen.
Schritt 4
Sobald Sie einen KPI für das Nutzerverhalten ausgewählt haben, ist es an der Zeit, den Deckungsbeitrag zu berechnen.
Multiplizieren Sie dann den täglichen Deckungsbeitrag jedes Kanals mit den kumulierten Werbeumsätzen, die an jedem Tag erzielt werden.
Dieser Prozess setzt voraus, dass die Daten zum Nutzerverhalten pro Kanal gemessen werden und täglich zugänglich sind, so dass der Deckungsbeitrag aller Kanäle mit den Umsatzdaten jedes neuen Tages berechnet werden kann.
Hinweis: Obwohl wir hier zur Veranschaulichung nur vier Werbekanäle einbeziehen, sollten Sie hier auch Ihre organischen und anderen Kanaldaten einbeziehen, um die täglichen Umsätze vollständig dem täglichen Nutzerverhalten zuordnen zu können.
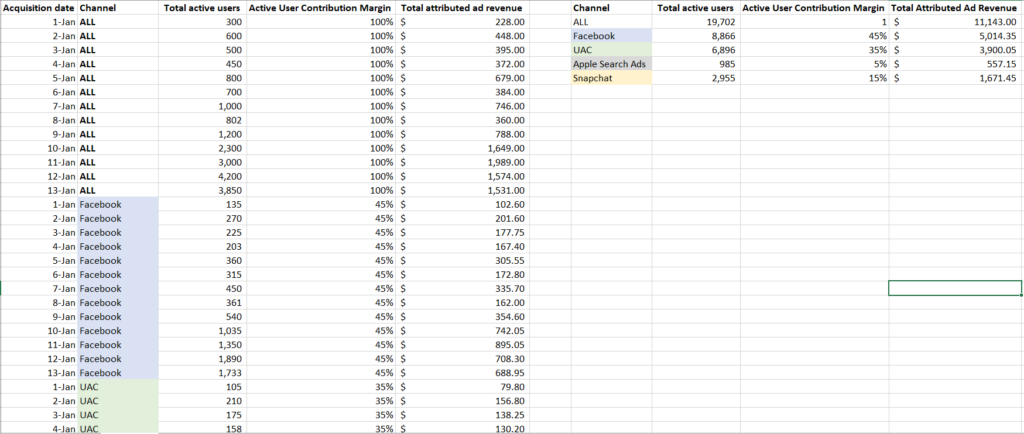
Oben sehen Sie die berechneten Werbeumsätze, die pro Tag und Kanal generiert werden, wodurch Sie die Profitabilität der einzelnen Kanäle abschätzen können.
Beachten Sie, dass Sie Ihre Einschätzung nützlicher KPIs für die Attribution von Werbeumsätzen überdenken müssen, wenn sich Trends im Nutzerverhalten und Daten zur Monetarisierung von Werbeumsätzen ändern oder neue Datenpunkte verfügbar werden.
Im obigen Datensatz ist beispielsweise gegen Ende des Berichtszeitraums (etwa ab dem 10. Januar) eine zweite Gruppierung von Datenpunkten zu erkennen, bei der deutlich mehr tägliche Werbeumsätze zu verzeichnen sind als zu Beginn des Monats.
Dies spiegelt sich in der Gruppierung der Daten im rechten oberen Bereich jedes Streudiagramms wider, weg von der Gruppe unten links.
Je komplexer der Datensatz ist, desto ungenauer ist diese einfache Excel-Regressionsanalyse, und desto größer ist die Notwendigkeit, eine Segmentierung und eine genauere Analyse durchzuführen.

Auf dem Weg in eine neue Werberealität
Prädiktive Analysen ermöglichen es Ihnen, die potenzielle Zielgruppe Ihrer Kampagne zu vergrößern, den LTV der Nutzer zu erhöhen und eine effizientere Budgetierung zu gewährleisten – und das in einer Zeit, in der wir in einigen Fällen keinen Zugang mehr zu detaillierten Performance-Daten haben.
Indem Sie verschiedene Cluster von Verhaltensmerkmalen erstellen, können Sie Ihre Zielgruppe nicht nach ihrer tatsächlichen Identität, sondern nach ihrer Interaktion mit Ihrem Funnel in seinen frühesten Phasen kategorisieren. Diese Interaktion kann auf ihr zukünftiges Potenzial hinweisen, Ihrem Produkt einen bedeutenden Wert zu verleihen.
Die Kombination der wichtigsten Faktoren für Engagement, Retention und Monetarisierung kann die Kompatibilität eines Nutzers mit der LTV-Logik eines jeden Entwicklers korrelieren und eine pLTV-Angabe (Predicted Lifetime Value) gleich zu Beginn einer Kampagne liefern.
Maschinelles Lernen – der Schlüssel zum Erfolg
Eine Mobile App kann mehr als 200 Metriken für die Messung aufweisen, aber ein typischer Marketer wird wahrscheinlich nur maximal 25 messen. Eine Maschine hingegen ist in der Lage, all diese Informationen innerhalb von Millisekunden zu erfassen und sie für Marketing-Insights und Indikatoren der App-Funktionalität zu nutzen.
Ein Algorithmus für maschinelles Lernen ist in der Lage, all diese Indikatoren zu berechnen und die richtigen Korrelationen für Sie zu finden. Die Berechnungen basieren auf Ihrer Definition von Erfolg, Ihrer LTV-Logik, und diese wird auf eine beträchtliche Datenmenge angewandt, um eine Korrelation zwischen frühen Engagement-Signalen und letztendlichem Erfolg zu finden.
Das bedeutet, dass Werbetreibende nicht mehr wissen müssen, WER der/die Nutzer:in ist, sondern vielmehr, WELCHEM pLTV-Profil und welchen Merkmalen er/sie entspricht. Dieses Profil sollte so genau wie möglich sein und bereits in den ersten Tagen der Kampagne zur Verfügung gestellt werden. Er sollte den LTV-Anforderungen des Werbetreibenden entsprechen, um als gültig und umsetzbar zu gelten.
Bei E-Commerce-Apps beispielsweise ermöglicht die Berücksichtigung von Indikatoren wie frühere Käufe, Kaufhäufigkeit, Tageszeit oder Funnel-Progression dem Algorithmus, allgemeine Zielgruppen in hochgranulare, sich gegenseitig ausschließende Kohorten einzuteilen.
Dies ermöglicht ein effektiveres Targeting und Messaging und letztlich einen höheren ROAS.
Nutzung von Cluster-LTV-Prognosen
Prädiktive Analysen helfen dabei, die Lernphase der Kampagne zu verkürzen, indem bestehende Integrationen genutzt werden, um eine genaue LTV-Prognose für die Kampagne zu erstellen.
Mit Hilfe von maschinellem Lernen und dem Verständnis aggregierter Daten könnte die prädiktive Analyse bereits wenige Tage nach dem Start einer Kampagne potenzielle Hinweise in Form eines Scores, Rankings oder einer anderen Form von verwertbaren Erkenntnissen liefern, die den Marketern Aufschluss darüber geben, wie erfolgreich die Kampagne sein wird.
Beispielsweise, mit KI einer Gaming-App, wurde herausgefunden, dass Nutzer:innen, die Level 10 eines Games innerhalb der ersten 24 Stunden abschließen, mit 50 % höherer Wahrscheinlichkeit zu zahlenden Nutzern werden.
Anhand dieser Informationen können Marketers entweder ihre Verluste bei einer schlechten Kampagne, die keine qualitativ hochwertigen Nutzer:innen liefert, begrenzen, bei Bedarf optimieren oder den Einsatz verdoppeln, wenn frühe Anzeichen auf einen potenziellen Gewinn hindeuten, wodurch sie in der Lage sind, schnelle Pausen-Boost-Optimierungs-Entscheidungen zu treffen.
Die SKAdNetwork Herausforderung
Die Einführung der datenschutzorientierten Realität von iOS 14 und Apples SKAdNetwork hat eine Reihe eigener Herausforderungen mit sich gebracht, vor allem die Beschränkung der Messung von Nutzerdaten im iOS-Ökosystem auf zustimmende Nutzer:innen.
Es wird davon ausgegangen, dass dies nur der erste Schritt in Richtung eines stärker auf den Schutz der Privatsphäre der Nutzer:innen ausgerichteten Werbeumfelds ist und dass viele große Akteure der Online-Branche wahrscheinlich nachziehen werden – in der einen oder anderen Form.
Diese Veränderungen schränken nicht nur die Menge der verfügbaren Daten ein, sondern auch das Zeitfenster, in dem Marketer fundierte Entscheidungen darüber treffen können, ob eine Kampagne erfolgreich sein wird oder nicht.
Obwohl Algorithmen des maschinellen Lernens schnell vorhersagen können, welche Kampagnen wahrscheinlich die wertvollsten Kunden bringen, gibt es weitere Einschränkungen, wie z. B. das Fehlen von Echtzeitdaten, keine ROI- oder LTV-Daten, da hauptsächlich Installationen gemessen werden, und ein Mangel an Granularität, da nur Daten auf Kampagnenebene verfügbar sind.
Wie können Sie also relevante Werbung schalten, ohne zu wissen, welche Aktionen die einzelnen Nutzer:innen durchführen?
Sie haben es erraten: Auf maschinellem Lernen basierendes prädiktives Marketing. Mithilfe fortschrittlicher statistischer Korrelationen, die auf historischen App-Verhaltensdaten basieren, um zukünftige Aktionen vorherzusagen, können Marketer Experimente mit nicht personalisierten Parametern durchführen, wie z. B. kontextbezogene Signale und kontinuierliches Training von Machine-Learning-Modellen.
Die Ergebnisse können dann auf zukünftige Kampagnen angewendet und weiter verfeinert werden, wenn mehr Daten gesammelt werden.

1. Füttere die Bestie
Bei der Erstellung von Datenmodellen, die als Grundlage für wichtige Entscheidungen dienen, ist es nicht nur wichtig, ein bestmögliches System zu entwickeln, sondern auch kontinuierliche Tests durchzuführen, um seine Effektivität zu gewährleisten.
Für beide Zwecke sollten Sie sicherstellen, dass Sie Ihr Prognosemodell kontinuierlich mit den relevantesten Daten füttern, um es zu trainieren.
Überprüfen Sie außerdem immer, ob die Prognosen Ihres Modells auf der Grundlage neuer Beobachtungen zutreffen oder zumindest nahe daran liegen.
Werden diese Schritte nicht befolgt, kann ein Modell mit einer anfänglich nützlichen Prognosekraft je nach Saisonalität, Makro-Auktionsdynamik, Monetarisierungstrends Ihrer App oder vielen anderen Gründen aus dem Ruder laufen.
Indem Sie Ihre Frühindikatoren oder frühen Benchmarks beobachten und nach signifikanten Veränderungen der Datenpunkte Ausschau halten, können Sie abschätzen, wann auch Ihre eigenen Prognosen wahrscheinlich scheitern werden.
Wenn Ihr Modell beispielsweise auf Daten trainiert wurde, bei denen die durchschnittliche Retentionsrate am ersten Tag zwischen 40 % und 50 % lag, die Retentionsrate am ersten Tag aber innerhalb einer Woche auf 30 % bis 40 % gesunken ist, könnte dies darauf hindeuten, dass Sie Ihr Modell neu trainieren müssen.
Das gilt vor allem, wenn sich die Qualitätssignale der zuletzt gewonnenen Nutzer:innen verändert haben, was bei sonst gleichen Bedingungen zu Änderungen bei der Monetarisierung und dem Profit führen dürfte.
2. Wählen Sie den richtigen KPI für die Profitabilitätsvorhersage
Es stehen mehrere Optionen zur Verfügung, von denen jede eine Reihe von Kompromissen hinsichtlich Realisierbarkeit, Genauigkeit und Geschwindigkeit bei der Erstellung von Empfehlungen eingeht.
Testen Sie verschiedene KPIs (z. B. mehr oder weniger Tage ROAS oder LTV) und nutzen Sie eine oder alle der folgenden Möglichkeiten, um den Profit von mehreren KPIs zu vergleichen:
- R-Quadrat
- Ein Verhältnis von Erfolg zu Misserfolg bei zufriedenstellender Prognose
- Mean Absolute Percentage Error (MAPE)
Sie werden überrascht sein, wie schlecht die Standardmaße korreliert sind.
3. Segmentieren Sie Ihre Daten
Die Segmentierung von Nutzern in homogenere Gruppen ist nicht nur eine gute Möglichkeit, die Conversion Rate zu verbessern, sondern auch eine bewährte Methode, Störungen zu reduzieren und die Prognosen Ihres Modells zu verbessern.
Beispielsweise könnte es zu weniger effektiven Ergebnissen führen, wenn dasselbe Modell sowohl auf interessenbasierte Kampagnen als auch auf wertbasierte Lookalike-Kampagnen angewendet wird. Der Grund dafür ist, dass die Monetarisierung und die Lebensdauer der Nutzer:innen der einzelnen Zielgruppen wahrscheinlich sehr unterschiedlich sind.
Außerdem kann Ihre Zielgruppe anhand verschiedener Verhaltenscharakteristiken kategorisiert werden, und zwar nicht nach ihrer tatsächlichen Identität, sondern nach ihrer Interaktion mit Ihrer Kampagne in der Anfangsphase. Diese Interaktion kann ihr zukünftiges Potenzial mit Ihrem Produkt aufzeigen.
So kann beispielsweise ein Gaming-App-Entwickler den potenziellen LTV vorhersagen, den er in einem Zeitraum von 30 Tagen aus seinen Nutzern herausholen kann. Mit anderen Worten: die Zeitspanne bis zum Ende des Tutorials (Engagement), die Anzahl der Besuche in der App (Retention) oder das Ausmaß der Werbung bei jeder Session (Monetarisierung).
4. Denken Sie daran, Zeit einzukalkulieren
Die meisten Marketer sind sich des Einflusses der Saisonalität auf die Aufschlüsselung von Prognosen bewusst, aber auch der Lebenszyklus Ihrer App/Kampagne/Zielgruppe/Creative kann die Fähigkeit Ihres Modells, genaue Prognosen zu erstellen, beeinflussen.
Die Trends bei den Akquisitionskosten in der ersten Woche einer neuen App-Einführung werden sich von denen im fünften Monat, im zweiten Jahr usw. deutlich unterscheiden, ebenso wie die ersten 1.000 US-Dollar an Ausgaben für ein bisher unerschlossenes Lookalike sich von den 10.000 und 50.000 US-Dollar an Ausgaben für dasselbe Lookalike unterscheiden werden (insbesondere ohne Änderung der genutzten Creative).

- Die Wissenschaft der prädiktiven Analysen gibt es schon seit Jahren, und sie wird von den weltweit größten Unternehmen genutzt, um ihre Abläufe zu perfektionieren, Angebots- und Nachfrageverschiebungen zu antizipieren, globale Veränderungen vorherzusehen und historische Daten zu nutzen, um zukünftige Events zu antizipieren und vorzubereiten.
- Auf dem Weg in eine neue, datenschutzorientierte Realität müssen wir einen neuen Messstandard annehmen – einen, der kürzere Messzeiträume erfordert und anonyme Angaben zum Nutzerpotenzial für die Entscheidungsfindung anwendet.
- Die prädiktive Modellierung bietet genau das. Die Einführung dieser hochentwickelten Technologie in die Marketinglandschaft und ihre Umsetzung, um der Entwicklung der Branche entgegenzukommen, ist von höchster Bedeutung.
