


Introducción
Introduciendo una mentalidad de marketing más rápida y basada en los datos
Hoy en día, los consumidores tienen más opciones que nunca. Pueden aprovechar fácilmente sus habilidades de desplazamiento para conseguir prácticamente lo que quieran, cuando quieran. Impulsada por la pandemia y una creciente demanda de servicios y entretenimiento digitales, la competencia en el mercado de las aplicaciones se ha vuelto más feroz que nunca.
Mantenerse un paso por delante de la curva es la única manera de seguir siendo competitivo. Y el modelado predictivo permite precisamente eso, ayudar a los marketers a comprender los comportamientos y tendencias de los consumidores, predecir acciones futuras y planificar sus campañas basándose en decisiones basadas en datos.
La ciencia del análisis predictivo existe desde hace años, y la utilizan las mayores empresas del mundo para perfeccionar sus operaciones, anticiparse a los cambios de la oferta y la demanda, prever cambios globales y utilizar datos históricos para prepararse mejor ante acontecimientos futuros.
Pero, ¿qué es esta extraña creación de la ciencia de datos y el marketing?
El modelado predictivo es una forma de análisis que aprovecha el aprendizaje automático y la IA para examinar datos históricos de campañas, datos de comportamiento de usuarios anteriores y datos transaccionales adicionales para predecir acciones futuras.
Mediante el uso de modelos predictivos, los profesionales del marketing pueden tomar decisiones rápidas de optimización de campañas sin tener que esperar a que lleguen los resultados reales. Por ejemplo, un algoritmo de aprendizaje automático ha descubierto que los usuarios que completaron el nivel 10 de un juego en las primeras 24 horas tenían un 80% más de probabilidades de realizar una compra dentro de la aplicación durante la primera semana.
Armados con este conocimiento, los marketers pueden optimizar después de que se alcance ese evento en 24 horas, mucho antes de que haya transcurrido la primera semana. Si la campaña no funciona bien, seguir invirtiendo sería un completo desperdicio de presupuesto. Pero si lo es, redoblar rápidamente la inversión puede generar resultados aún mejores.
¿Y la privacidad?
¿Qué impacto tiene la privacidad en el modelado predictivo ahora que hay un acceso limitado a los datos a nivel de usuario?
Es un hecho conocido que los usuarios móviles se han vuelto cada vez más sofisticados e informados en los últimos años. Con la privacidad (o la falta de ella) en el centro de la escena, el usuario medio de aplicaciones ya no tiene prisa por facilitar sus datos para utilizar una aplicación, ni siquiera para disfrutar de una experiencia más personalizada.
Pero, hoy en día, ¿los anunciantes realmente se quedan a oscuras cuando se trata de acceder a datos de calidad?
La respuesta corta es que no necesariamente. Mediante la combinación de modelos predictivos, SKAdNetwork, datos agregados y análisis de cohortes, los profesionales del marketing pueden tomar decisiones informadas incluso en una realidad limitada por el IDFA.
¿Por dónde empezar? Una cosa es medir los acontecimientos, controlar el rendimiento y optimizar. Otra cosa muy distinta es analizar una cantidad ingente de datos, así como desarrollar y aplicar modelos predictivos que te permitan tomar decisiones ágiles y precisas basadas en datos.
Pues no temas. Estamos aquí para ayudarte a entenderlo todo.
En esta guía práctica, fruto de la colaboración entre AppsFlyer, la agencia de marketing digital AppAgent e Incipia, exploraremos cómo los marketers pueden llevar sus conocimientos de datos al siguiente nivel y obtener esa codiciada ventaja competitiva con el modelado predictivo.

Modelización predictiva: Conceptos básicos y configuración de las mediciones
¿Por qué crear modelos predictivos?
El modelado predictivo tiene numerosas ventajas para el marketing móvil, pero lo hemos reducido a dos actividades de marketing clave:
1. Adquisición de usuarios
Conocer el comportamiento típico de los usuarios y los primeros hitos que separan a los usuarios con alto potencial de los usuarios con bajo potencial puede ser útil tanto en el frente de la adquisición como en el del reengagement.
Por ejemplo, si un usuario necesita generar X dólares en el día 3 para obtener beneficios después del día 30, y esa cifra está por debajo de tu benchmark, sabrás que necesitarás ajustar las ofertas, las creatividades, la segmentación u otras cosas para mejorar el costo/calidad de tus usuarios adquiridos, o bien mejorar tus tendencias de monetización.
Si, por el contrario, ese X supera tu benchmark, puedes confiar en aumentar los presupuestos y las ofertas para obtener aún más valor de los usuarios adquiridos.
2. Publicidad centrada en la privacidad
Durante años, la mayor ventaja de la publicidad en línea sobre la publicidad tradicional ha sido la capacidad de utilizar cantidades significativas de datos de rendimiento medibles para determinar con precisión el público objetivo deseado.
Cuanto más específicas sean tus campañas, más probabilidades tendrás de conseguir un mayor LTV de los usuarios y un presupuesto más eficiente. Pero, ¿y si pudieras abrir las puertas a un grupo de muestra más amplio y obtener insights inmediatos sobre su valor potencial?
El modelado predictivo te permite hacer exactamente eso: ampliar la audiencia potencial de tu campaña. Mediante la creación de diferentes grupos de características de comportamiento, tu audiencia puede segmentarse no por su identidad, sino por su interacción con tu campaña en sus primeras etapas.
¿Qué debo medir?
Para saber qué hay que medir para acertar en las predicciones, veamos qué datos son útiles y cuáles no:
Métricas
Al igual que la relación entre el cuadrado y el rectángulo: todas las métricas son puntos de datos, pero no todas las métricas son indicadores clave de rendimiento (KPI). Las métricas son más fáciles de calcular y maduran mucho más rápido que los KPIs, que suelen implicar fórmulas complejas.
Ten en cuenta que con SKAdNetwork de Apple, las siguientes métricas todavía se pueden medir, pero con un menor nivel de precisión. Más información en el capítulo 5.
1) Las métricas heredadas suelen identificarse con una confianza baja en la predicción de beneficios, pero tienen la disponibilidad más rápida:
- Click-to-install (CTI): la conversión directa entre los dos touchpoints más importantes en el viaje del usuario previo a la instalación. El CTI es fundamental tanto desde el punto de vista social como técnico, ya que los índices más bajos podrían indicar una audiencia no relevante, creatividades ineficaces o un tiempo de carga lento antes de completar la instalación.
Fórmula: Número de instalaciones / Número de clics en anuncios
- Tasa de click-through (CTR): relación entre un clic en un anuncio determinado y el número total de visualizaciones. Más arriba en el embudo, el CTR tiene un valor limitado para informar sobre otros objetivos generales de marketing, pero puede reflejar directamente la eficacia de la creatividad de una campaña en función de los clics recibidos.
Número de clics / Número de visualizaciones del anuncio
Datos necesarios: impresiones, clics, instalaciones atribuidas
2) Las métricas de indicadores tempranos suelen identificarse con una confianza media en la predicción de beneficios y disponibilidad rápida.
En la era del enfoque “down-funnel”, una instalación ya no es un KPI suficiente. Dicho esto, las siguientes métricas, aunque no son útiles para predecir los beneficios, sí lo son como indicadores tempranos que informan a los marketers sobre la probabilidad de que sus campañas generen beneficios.
Algunos ejemplos son:
- Costo por instalación (CPI): centrado en las instalaciones de pago más que en las orgánicas, el CPI mide los costos de tu UA en respuesta a la visualización de un anuncio.
Fórmula: Gasto en publicidad / Número total de instalaciones directamente vinculadas a la campaña publicitaria
- Tasa de retención: número de usuarios que regresan tras un periodo de tiempo determinado.
Cálculo: [(CE – CN) / CS)] X 100
CE = número de usuarios al final del periodo
CN = número de nuevos usuarios adquiridos durante el periodo
CS = número de usuarios al inicio del periodo
Datos necesarios: costo, instalaciones atribuidas, aperturas de aplicaciones (reporte de retención).
Con la excepción de la tasa de retención, las métricas tienden a estar vinculadas a un modelo de marketing más que a tu modelo de negocio y, como tales, no son útiles para determinar si los usuarios adquiridos supondrán un beneficio para su empresa.
Si pagas 100 dólares por clic o por instalación, lo más probable es que no obtengas beneficios. Si tu CTR es del 0,05%, es probable que la mecánica de la subasta te obligue a pagar una tarifa alta por instalación, dejándote una vez más con menos margen para obtener beneficios.
Las métricas no apoyan las predicciones cuando se intenta calibrar el intervalo de confianza con mayor precisión, por ejemplo, cuando la línea de rentabilidad se sitúa en un intervalo de 2 a 6 dólares del CPI.
KPIs
Es importante subdividir los KPIs comunes en dos categorías:
1) Predictores de confianza de KPIs de nivel 2 : definidos por una confianza media-alta en la predicción de beneficios y disponibilidad lenta:
Los KPIs de nivel 2 tardan más tiempo en madurar y también ofrecen menos confianza que los KPIs de nivel 1. Los KPIs de nivel 2 son útiles como benchmarks tempranos de los beneficios y ofrecen más confianza que los indicadores adelantados (métricas).
* Ten en cuenta que con SKAdNetwork de Apple, los siguientes KPIs no pueden medirse conjuntamente.
- Costo de adquisición de clientes por usuario de pago
- Costo o conversión de acciones clave: por ejemplo, ratio de partidas jugadas el primer día, o ratio de visualizaciones de contenidos durante la primera sesión.
- Costo basado en el tiempo o en la conversión de acciones clave (por ejemplo, costo por número de partidos jugados en el primer día o costo por visualización de contenidos durante la primera sesión).
- Costo por día X para un usuario retenido: Gasto total por día * X número de usuarios retenidos en ese día.
- Eventos verticales específicos dentro de la aplicación: por ejemplo, finalización del tutorial, finalización del nivel 5 el primer día (juegos), número de páginas de productos vistas en la primera sesión, número de sesiones en 24 horas (compras), etc.
Puntos de datos necesarios: costo, instalaciones atribuidas, aperturas de la aplicación (reporte de retención), eventos in-app configurados y medidos, datos de la sesión (marcas de tiempo, funciones utilizadas, etc.).
Para la mayoría de los modelos de negocio, estos KPIs no pueden servir como predictores fiables porque, aunque tienen en cuenta los costos y los eventos habitualmente correlacionados con los beneficios, no tienen en cuenta el lado de la monetización de la ecuación de beneficios, dado que las aperturas de aplicaciones no siempre equivalen al gasto dentro de la aplicación, y los usuarios que pagan pueden comprar más de una vez.
2) Indicadores clave de rendimiento (KPIs) de nivel 1 – predictores fiables: los ingresos tempranos y el consiguiente ROAS como indicación de éxito a largo plazo, marcados con una alta confianza en la predicción de beneficios, pero con la disponibilidad más lenta:
Los KPI de nivel 1 tardan más tiempo en madurar por completo o implican procesos complejos para su determinación. Sin embargo, están directamente relacionados con tu modelo de negocio y, como tales, son perfectamente adecuados para predecir la rentabilidad de tus campañas de marketing.
- Retorno de la inversión publicitario (ROAS): Es el dinero gastado en marketing dividido por los ingresos generados por los usuarios en un periodo de tiempo determinado.
Lifetime Value (LTV) – La cantidad de ingresos que los usuarios han generado para tu aplicación hasta la fecha.
Fórmula: Valor medio de una conversión X Número medio de conversiones en un periodo X Vida media del cliente
Puntos de datos necesarios: costo, instalaciones atribuidas, aperturas de aplicaciones, medición de ingresos en profundidad (IAP, IAA, suscripción, etc.)
Mientras que el ROAS es más fácil de calcular, requiere semanas o incluso meses para que los usuarios sigan generando curvas de ingresos. Combinado con el ingreso medio por usuario, el LTV es una métrica de oro para determinar los posibles ingresos totales o el valor de tus usuarios.
Para terminar, aquí es dónde cada enfoque se sitúa en el siguiente gráfico:
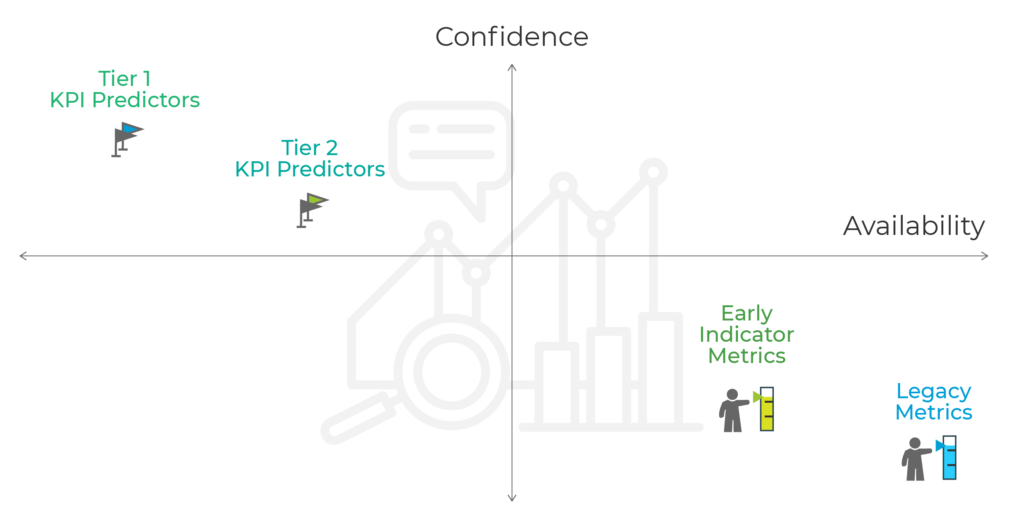

Pros y contras de los distintos modelos de predicción basados en el LTV: Insights de los mejores marketers
Construir un modelo LTV para predecir el ROAS podría ser abrumador dada la enorme complejidad y los múltiples conceptos de predicción que existen.
Hay diferencias obvias en la forma en que los distintos tipos de aplicaciones retienen y monetizan a los usuarios; basta pensar en lo distintos que son los juegos con compras in-app, las aplicaciones basadas en suscripciones y los negocios de eCommerce.
Está claro que no puede existir un modelo único de LTV.
Para entender mejor las complejidades, hemos hablado con varios expertos de empresas de juegos y de otros sectores, como Hutch Games, Wargaming, Pixel Federation y Wolt, entre otras.
Estas son las principales cuestiones que hemos tratado:
- ¿Qué modelos de LTV utilizas?
- ¿Cómo evoluciona tu modelo LTV con el tiempo?
- ¿Quién se encarga en la empresa de la modelización predictiva?
- ¿Cuál es tu métrica estrella en UA?
- ¿Qué opinas de la automatización de UA y de las tendencias futuras?
Modelos LTV
Según nuestras entrevistas, parece que hay tres “escuelas de pensamiento” principales para las predicciones de LTV:
1) Modelo de retención basado en la retención / ARPDAU
- Concepto: Modela una curva de retención basada en un par de puntos de datos de retención iniciales, luego calcula el número medio de días activos por usuario (para el Día 90, D180, etc.) y multiplícalo por un Ingreso Medio por Usuario Activo Diario (ARPDAU) para obtener el LTV previsto.
- Ejemplo: La retención de D1 / D3 / D7 es del 50% / 35% / 25%. Tras ajustar estos puntos de datos a una curva de potencia y calcular su integral hasta D90, comprobamos que el número medio de días activos es de 5. Sabiendo que el ARPDAU es de 40 céntimos, el LTV previsto para D90 sería igual a 2 USD.
- Buen ajuste: Aplicaciones de alta retención (juegos como MMX Racing). Fácil de configurar, puede ser útil sobre todo si no hay datos suficientes para otros modelos.
- Mal ajuste: Aplicaciones de baja retención (por ejemplo, eCommerce) que no pueden acceder a un número suficiente de puntos de datos de retención para sostener este modelo.
2) En función de la relación
- Concepto: Calcula un coeficiente (VTL D90 / VTL D3) a partir de los datos históricos y, a continuación, para cada cohorte y, por último, aplica este coeficiente para multiplicar el VTL D3 real y obtener una predicción del VTL D90.
- Ejemplo: Después de los 3 primeros días, el ARPU de nuestra cohorte es de 20 céntimos. Utilizando datos históricos, sabemos que D90/D3 = 3. Por lo tanto, el LTV previsto para D90 sería de 60 céntimos (20 céntimos ARPU*3).
- En caso de que no haya suficientes datos históricos para calcular un ratio fiable (es decir, sólo tenemos 50 días de datos y queremos una predicción de la VTL D180, o tenemos muy pocas muestras de la VTL D180), se puede hacer una estimación inicial utilizando los puntos de datos existentes, y luego refinarla continuamente a medida que lleguen más datos.
Pero en estos casos, es necesario tomar tales estimaciones con un gran grano de sal.
- Buen ajuste: Tipos “estándar” de aplicaciones, incluidos muchos géneros de juegos o aplicaciones de eCommerce.
- Mal ajuste: Aplicaciones por suscripción con más de una semana de prueba gratuita. Puedes pasar mucho tiempo antes de que se produzca una compra, y como este método se basa en la compra, haría imposible una predicción.
3) Predicciones basadas en el comportamiento
- Concepto: Recopilación de un volumen significativo de datos de usuarios de aplicaciones con consentimiento (datos de sesión y compromiso, compras, mensajes in-app, etc.) y procesamiento mediante regresiones y aprendizaje automático para definir qué acciones o combinaciones de acciones son los mejores “predictores” del valor de un nuevo usuario.
A continuación, un algoritmo asigna un valor a cada nuevo usuario en función de una combinación de características (por ejemplo, plataforma o canal UA) y acciones realizadas (a menudo durante unas pocas sesiones o días iniciales).
Es importante mencionar que desde el lanzamiento de las restricciones de privacidad de Apple con iOS 14, las predicciones a nivel de usuario no son posibles. Dicho esto, las predicciones agregadas de los usuarios sí lo son.
- Ejemplo: El usuario A tuvo 7 sesiones largas el día 0 y, en total, 28 sesiones el día 3. También visitaron la página de precios y permanecieron en ella más de 60 segundos.
La probabilidad de que realicen una compra en el futuro es del 65%, según el análisis de regresión y el algoritmo basado en aprendizaje automático. Con un ARPPU de 100 USD, su LTV previsto es, por tanto, de 65 USD.
- Buen ajuste: Cualquier aplicación con acceso a un equipo científico de datos experimentado, recursos de ingeniería y muchos datos. Podría ser una de las pocas opciones viables en algunos casos (por ejemplo, aplicaciones de suscripción con una larga prueba gratuita).
- Mal ajuste: Puede resultar excesivo para muchas aplicaciones pequeñas y medianas. La mayoría de las veces, enfoques mucho más sencillos pueden dar resultados similares, son mucho más fáciles de mantener y de entender por el resto del equipo.
Elegir el modelo adecuado para cada tipo de aplicación
Cada aplicación y cada equipo tienen sus propios parámetros y consideraciones que deben tenerse en cuenta en el proceso de selección:
- En cuanto al producto, se trata de una combinación única de tipo y categoría de aplicación, modelo de monetización, comportamiento de compra del usuario y datos disponibles (y su varianza).
- Por parte del equipo, se trata de la capacidad, la competencia en ingeniería, los conocimientos y el tiempo disponible antes de que el modelo de trabajo sea requerido por el equipo de UA.
En esta sección, esbozaremos varios ejemplos simplificados del proceso de selección.
Se basan en casos reales de tres tipos de aplicaciones: un juego free-to-play (F2P), una aplicación por suscripción y una aplicación de eCommerce.

Aplicaciones por suscripción
Analicemos dos casos de aplicaciones basadas en suscripciones, cada una con un tipo diferente de muro de pago (paywall): una puerta dura y una prueba gratuita por tiempo limitado:
1. El duro paywall: La suscripción de pago comienza muy a menudo durante el día 0 (por ejemplo, 8fit).
Esto es estupendo: significa que tendremos una indicación muy precisa del número total de suscriptores ya después del primer día (por ejemplo, digamos que el 80% de todos los suscriptores lo hagan el D0, y el 20% restante, en algún momento futuro).
Siempre que conozcamos nuestras tasas de abandono y, por consiguiente, nuestro ARPPU, podríamos predecir fácilmente el LTV de las cohortes simplemente multiplicando (número de pagadores)*(ARPPU para un segmento de usuarios determinado)*(1,25 como coeficiente que representa el 20% adicional estimado de usuarios que se espera que paguen en el futuro).
2. Prueba gratuita por tiempo limitado: En este caso, un porcentaje de los usuarios se convertirán en suscriptores de pago una vez finalizada la prueba (por ejemplo, Headspace). El problema es que los gestores de UA tienen que esperar a que termine la prueba para entender las tasas de conversión.
Este desfase puede ser especialmente problemático cuando se prueban nuevos canales y GEO, por lo que las predicciones de comportamiento podrían ser útiles en este caso.
Incluso con un volumen moderado de datos y regresiones sencillas, a menudo es posible identificar predictores decentes. Por ejemplo, podríamos saber que los usuarios que entran en la prueba gratuita y tienen al menos 3 sesiones al día durante los 3 primeros días tras la instalación – se convertirán en suscriptores en el 75% de los casos.
Aunque dista mucho de ser perfecto, el predictor anterior podría ser lo suficientemente preciso para la toma de decisiones de UA y proporcionar una buena capacidad de acción para el equipo de UA antes de que se recopilen más datos y se pruebe un modelo adecuado.
Los tipos y diseños de los muros de pago pueden verse muy influidos por la necesidad de evaluar rápidamente el tráfico.
Es muy útil saber si el usuario convertirá (o no) lo antes posible para comprender la rentabilidad de la campaña y poder reaccionar rápidamente. Hemos visto que esto se ha convertido en uno de los factores decisivos para varias empresas a la hora de determinar un tipo de paywall.
Juegos freemium
Los juegos free-to-play (F2P) tienden a tener un alto índice de retención y una cantidad significativa de compras.
1) Juegos casual (Diggy’s Adventure):
Un buen ajuste para los juegos basados en compras in-app es el “modelo de ratio”, en el que debería ser posible predecir con bastante confianza D(x)LTV después de 3 días, ya que para entonces deberíamos haber identificado a la mayoría de nuestros usuarios de pago.
Para algunos juegos que se monetizan mediante anuncios, también podría considerarse el enfoque basado en la retención.
2) Juegos hardcore (World of Tanks o MMX Racing):
La distribución de los ARPPU de los usuarios de juegos hardcore puede estar muy sesgada cuando los usuarios que más gastan, también conocidos como “ballenas”, pueden gastar x veces más que los demás.
El “modelo de ratio” podría seguir funcionando en estos casos, pero debería mejorarse para tener en cuenta los diferentes niveles de gasto de los distintos tipos de gastadores. En este caso, una variable de “tipo de usuario” asignaría diferentes valores de LTV a los usuarios en función de su comportamiento de gasto (es decir, cuánto gastaron, cuántas compras hicieron, qué paquete de inicio compraron, etc.).
En función de los datos, se podría hacer una primera predicción a partir del día 3, con otra pasada un poco más tarde (día 5 o día 7), una vez descubiertos los niveles de gasto de los usuarios.
Aplicaciones de eCommerce
Las aplicaciones de comercio electrónico suelen tener patrones de retención únicos, ya que su lanzamiento suele estar vinculado a una intención de compra existente, lo que no ocurre con demasiada frecuencia.
Por lo tanto, podemos concluir que el uso del “modelo basado en la retención” no suele ser adecuado para este tipo de aplicaciones. En su lugar, exploremos dos casos de uso alternativos:
1) Revendedor de billetes de avión
El tiempo que transcurre entre la instalación y la compra en los viajes es considerable, a veces de meses. Dado que las compras y los ingresos se distribuyen a lo largo de un periodo de tiempo prolongado, los modelos de “ratio” o “retención” no funcionarán en la mayoría de los casos.
Por lo tanto, debemos tratar de encontrar indicios de comportamiento y descubrir posibles factores de predicción en la primera sesión posterior a la instalación, ya que a menudo es la única información de la que dispondremos.
A partir de estos indicios, y si se dispone de datos suficientes, se calcula la probabilidad de que un usuario compre un billete y se multiplica por un ARPPU para una combinación pertinente de sus características (plataforma, país de origen, etc.).
2) Marketplace en línea
Los usuarios tienden a realizar su primera compra poco después de la instalación. Es más, ese primer artículo comprado suele tardar bastante en enviarse. Como resultado, los clientes tienden a esperar al primer envío para evaluar el servicio antes de comprometerse a otra compra.
Esperar al lote de datos de la “segunda compra” inutilizaría las predicciones debido al gran retraso, y posteriormente limitaría cualquier cálculo a los datos iniciales.
En función del momento en que los usuarios realizan sus pedidos (la mayoría lo hace en los 5 primeros días), podemos utilizar el método de la proporción (D90/D5) y multiplicar el resultado por otro coeficiente que tendría en cuenta las compras futuras.
Del MVP a los modelos complejos
Todos los analistas de datos con los que hablamos en las grandes editoriales coincidieron en que es importante iniciar el camino de las predicciones con un sencillo “producto mínimo viable” (MVP).
La idea es verificar los supuestos iniciales, aprender más sobre los datos y construir gradualmente un modelo. Esto suele significar añadir más variables a medida que se avanza para permitir modelos más granulares y precisos (por ejemplo, k-factor, estacionalidad e ingresos publicitarios, además de la segmentación inicial por plataforma, país y canal de UA).
Complejo no es sinónimo de “bueno”. Los gestores de UA pueden frustrarse rápidamente cuando su acceso a los datos está bloqueado porque alguien está haciendo cosas complicadas”.
Anna Yukhtenko, Data Analyst @Hutch Games
En realidad, hemos comprobado que las empresas tienden a adherirse a modelos conceptualmente sencillos.
Se trata de un hallazgo un tanto sorprendente. Esperábamos que, una vez que el producto despegara, los equipos de datos empezarían a escupir nubes de fuego, algoritmos de aprendizaje automático e IA para ponerse a la altura de lo que creíamos que era un estándar del sector. Estábamos equivocados. O al menos parcialmente.
Aunque muchos ven el valor de los modelos sofisticados y los han probado en el pasado, la mayoría se ha decantado finalmente por otros más sencillos. Hay tres razones principales para ello:
1. Costo/beneficio de los modelos avanzados
La relación costo/beneficio de crear y mantener un modelo complejo simplemente no cuadra. Si se puede alcanzar un nivel de confianza suficiente para las operaciones cotidianas con modelos más sencillos, ¿para qué molestarse?
2. Tiempo de ingeniería para crear/mantener
Crear un modelo avanzado puede consumir muchas horas de ingeniería, y aún más para gestionarlo, lo que supone un gran problema para los equipos más pequeños.
Muy a menudo, el departamento de BI tiene muy poca capacidad para dedicar al equipo de marketing, lo que deja a los marketers solos en una batalla desigual contra las estadísticas y la ingeniería de datos.
3. Cambios continuos
Cada versión del producto es diferente y se monetiza de forma distinta (añadir o eliminar funciones puede tener un efecto enorme, por ejemplo); la estacionalidad local y los efectos en todo el mercado son dos ejemplos relevantes.
Los cambios deben hacerse sobre la marcha, y la introducción de cambios en un modelo complejo puede ser un proceso doloroso y lento, que puede resultar desastroso en un entorno móvil en rápida evolución con compra continua de medios.
Es mucho más fácil ajustar un modelo sencillo, a veces por los propios marketers.
Para un determinado subgrupo de aplicaciones, un modelo basado en el comportamiento podría ser la única solución adecuada. Y aunque las empresas lo suficientemente grandes como para hacer frente a una inversión de este tipo deberían contar con un equipo experimentado de ingeniería y ciencia de datos, otras pueden optar por adoptar un producto ya preparado que ofrezca cualidades similares.
Otro conjunto de datos que está ganando adeptos son los modelos LTV generados por publicidad con estimaciones de ingresos publicitarios a nivel de usuario. Para más información, lee el capítulo 4.
Equipos y responsabilidades
En general, el diseño, la configuración y la adaptación de un modelo predictivo LTV debería ser una tarea para un equipo de análisis/ciencia de datos (siempre que exista uno).
Idealmente, hay dos papeles en juego aquí: un analista experimentado con un alcance al marketing que pueda asesorar sobre la estrategia y los niveles tácticos, así como decidir qué modelo se debe utilizar y cómo. Y un analista dedicado que “se encargue” de los cálculos y predicciones de LTV en el día a día.
El “analista del día a día” debe supervisar continuamente el modelo y estar atento a cualquier fluctuación significativa. Por ejemplo, si los ingresos semanales previstos no se ajustan a la realidad y no están dentro de los límites preestablecidos, puede ser necesario un ajuste del modelo inmediatamente, y no al cabo de unas semanas o meses.
“Es un trabajo de equipo. Creamos algo así como un sistema de alerta temprana en el que nos reunimos una vez al mes, repasamos todos los supuestos del modelo y comprobamos si siguen siendo ciertos. Hasta ahora, tenemos unas 12 hipótesis principales (por ejemplo, valor de los productos orgánicos incrementales, estacionalidad, etc.), que controlamos para asegurarnos de que vamos por el buen camino.”
Tim Mannveille, Director de Crecimiento e Insights @Hutch Games
Una vez calculados los resultados de la predicción, se transmiten automáticamente al equipo de UA que los utiliza. En la mayoría de los casos, los gestores de UA se basan simplemente en estos resultados e informan de las incoherencias, pero deberían intentar dar un paso más para poder cuestionar y evaluar mejor los modelos en uso a nivel general (no es necesario comprender los entresijos de un modelo complejo y sus cálculos).
Profesionales del marketing entrevistados para este capítulo:
- Fredrik Lucander de Wolt
- Andrey Evsa de Wargaming
- Matej Lancaric de Boombit (anteriormente en Pixel Federation)
- Anna Yukhtenko y Tim Mannveille de Hutch Games

Métodos para evaluar la rentabilidad del marketing móvil con Excel
Si crees que dominas el ámbito de Excel avanzado mediante el uso de tablas dinámicas, campos calculados, formato condicional y búsquedas, puede que te sorprenda saber que te estás perdiendo un truco aún más potente.
No sólo eso, sino que este truco puede utilizarse para predecir la rentabilidad de tus campañas de marketing móvil.
Considera el siguiente capítulo como tu miniguía para crear tus propios modelos predictivos utilizando herramientas cotidianas.
Descargo de responsabilidad: Ten en cuenta que lo que verá a seguir es una variación muy simplificada de un modelo predictivo. Para que funcionen correctamente a escala, se necesitan sofisticados algoritmos de aprendizaje automático que tengan en cuenta numerosos elementos que pueden afectar drásticamente a los resultados. Si sólo se tiene en cuenta un factor para predecir su valor (es decir, los ingresos), es probable que se carezca de precisión.
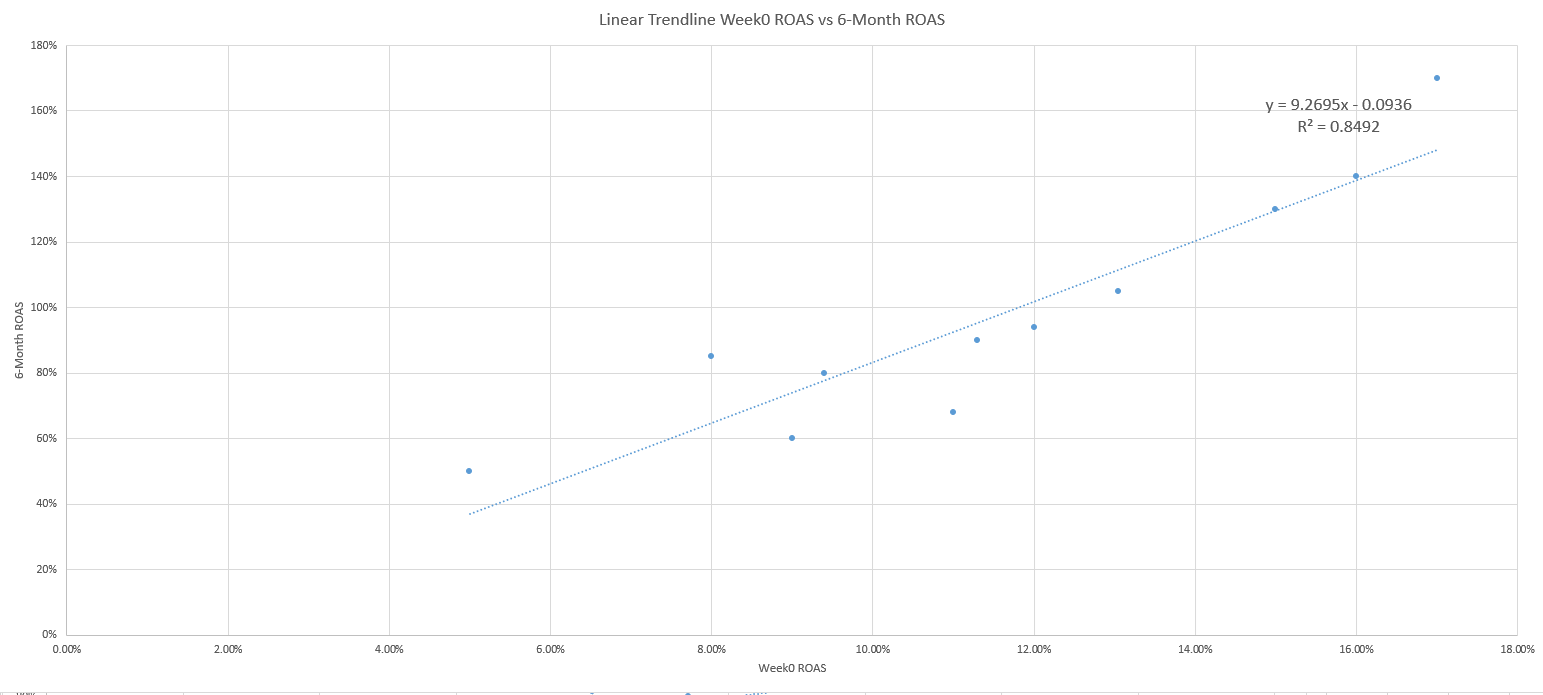
Utilizando un gráfico de dispersión y un poco de álgebra, puedes convertir una ecuación de línea de tendencia de Excel en una poderosa herramienta, como por ejemplo identificar con antelación el punto en el que tus campañas de marketing demuestran que es probable que generen beneficios.
Este método puede ayudarte a pasar de las suposiciones a la toma de decisiones basada en datos y a aumentar tu confianza en los reportes semanales.
Predecir qué ROAS de la semana 0 predice el 100% de ROAS a los 6 meses
Mientras que el LTV bien hecho es un gran predictor, el ROAS, especialmente en la primera semana de vida de un usuario, es una métrica muy utilizada para medir el beneficio debido a su amplia accesibilidad.
En concreto, vamos a utilizar el ROAS de la semana 0 (ingresos en la primera semana de adquisición de usuarios/costo de adquisición de esos usuarios) como nuestro predictor de confianza, que es un método cohorte de comparación del rendimiento publicitario cada semana.
El ROAS de la semana 0 nos permitirá predecir si alcanzaremos el punto de equilibrio en nuestro gasto publicitario con un ROAS del 100% al cabo de 6 meses.
Paso 1
El primer paso para utilizar Excel para predecir beneficios es asegurarte de que dispones de suficientes puntos de datos de la semana 0 y de los 6 meses. Aunque técnicamente se puede dibujar una pendiente y hacer una predicción para cualquier punto de esa pendiente con dos puntos de datos, la predicción estará lejos de ser sólida con tan pocas observaciones.
El número ideal de observaciones depende de una multitud de factores, como el nivel de confianza deseado, las correlaciones en el conjunto de datos y las limitaciones de tiempo, pero como regla general para las predicciones basadas en el ROAS de la semana 0, deberías intentar obtener al menos 60 pares de observaciones del ROAS de la semana 0 y de los 6 meses.
También es fundamental incluir suficientes observaciones que hayan alcanzado el nivel objetivo que se haya fijado. Si tienes 60 puntos de datos para trazar, pero sólo 2 puntos en los que el ROAS a 6 meses cruzó el 100%, entonces tu modelo de ecuación no estará lo suficientemente impulsado por una comprensión de qué insumos se requieren para alcanzar este punto de equilibrio.
En este caso, por lo que sabe tu modelo, el requisito para llegar al 100% de ROAS al cabo de 6 meses podría ser o bien otros 2 puntos porcentuales de ROAS completo o bien 5 puntos porcentuales, lo cual es un rango muy amplio que no es propicio para la predicción.
Paso 2
Una vez reunidas suficientes observaciones del nivel objetivo, el segundo paso consiste en dividir el conjunto de datos en dos grupos, uno para el entrenamiento y otro para la predicción.
Coloca la mayor parte de los datos (~80%) en el grupo de formación. Más adelante, utilizarás el grupo de predicción para comprobar la precisión de tu modelo a la hora de predecir el ROAS a 6 meses, teniendo en cuenta el ROAS de la semana 0.
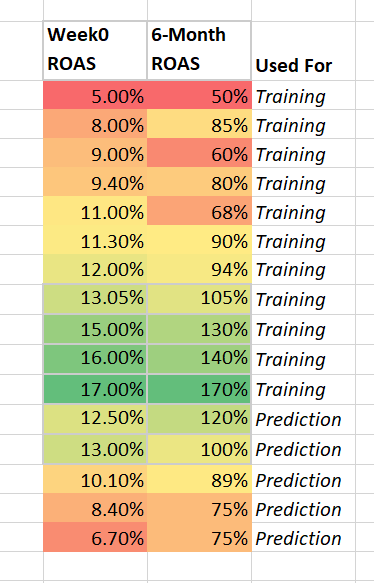
Paso 3
El tercer paso consiste en utilizar un diagrama de dispersión para representar gráficamente los datos, con el ROAS de la semana 0 en el eje de abscisas y el ROAS de 6 meses en el eje de ordenadas.
A continuación, añade una línea de tendencia y añade los ajustes de ecuación y R-cuadrado.
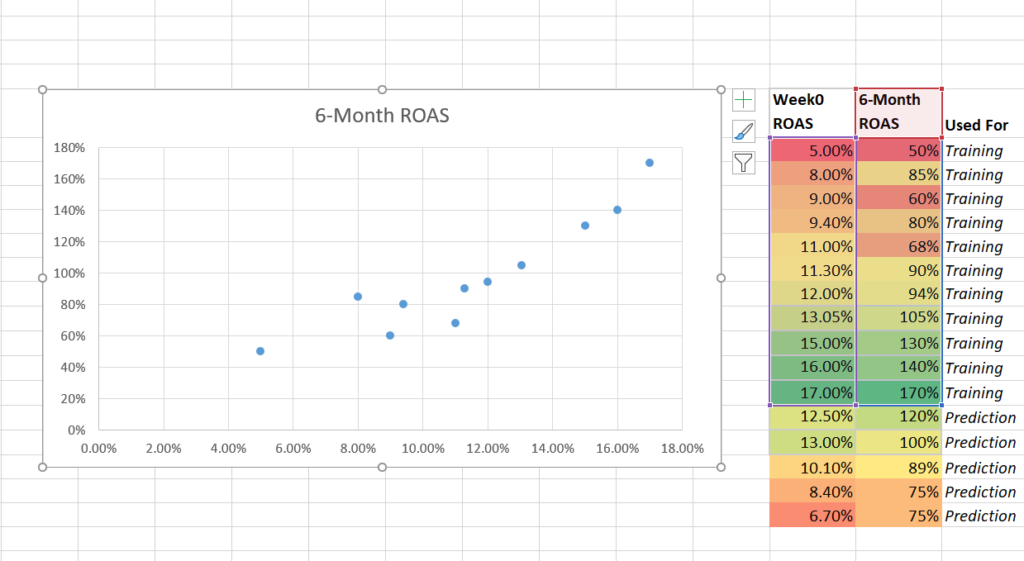
Representa gráficamente los datos de entrenamiento mediante un diagrama de dispersión.
Haga clic con el botón derecho en un punto de datos y añade una línea de tendencia.
Añade la ecuación de la línea de tendencia y R-cuadrado.
Paso 4
El cuarto paso consiste en utilizar la ecuación lineal y = mx + b para resolver el valor x de la ecuación (ROAS de la semana 0) cuando el valor y (ROAS de 6 meses) es 100%.
El reordenamiento de la ecuación mediante álgebra se realiza de la siguiente manera:
1. y = 9.2695x – .0936
2. 1 = 9.2695x – .0936
3. 1 + .0936 = 9.2695x
4. 1.0936 = 9.269x
5. X = 1.0936 / 9.269
6. X = 11.8%
De este modo, calculamos que la respuesta a la pregunta de cómo predecir el beneficio a los 6 meses es que tu ROAS debe ser superior al 11,8% en la primera semana.
Si tu ROAS de la Semana 0 está por debajo de esta tasa, sabrás que necesitarás ajustar las ofertas, las creatividades o la segmentación para mejorar el costo/calidad de tus usuarios adquiridos y mejorar tus tendencias de monetización.
Si tu ROAS de la semana 0 supera esta cifra, puedes sentirte seguro a la hora de aumentar los presupuestos y las ofertas.
Paso 5
En el quinto paso se utiliza el segmento de predicción del conjunto completo de datos para evaluar la capacidad del modelo para predecir los resultados reales. Esto puede evaluarse utilizando el porcentaje medio de error absoluto (MAPE), que es un cálculo que divide el valor absoluto del error (el valor real menos el valor previsto) por el valor real.
Cuanto menor sea la suma del MAPE, mejor será el poder predictivo de tu modelo.

No existe una regla empírica para calcular un buen MAPE, pero en general, cuantos más datos tenga el modelo y más correlacionados estén, mejor será la capacidad de predicción del modelo.
Si tu MAPE es alto y las tasas de error son inaceptables, puede ser necesario utilizar un modelo más complejo. Aunque son más difíciles de gestionar, los modelos que utilizan R y python) pueden aumentar el poder de predicción del análisis.
Y ahí lo tienen: un marco para predecir la rentabilidad de las campañas de marketing.
Pero no dejes de leer todavía. Esta guía tiene más ventajas a seguir.
Mejora tus predicciones
Para los lectores curiosos, la pregunta que les ronda por la cabeza puede ser si la línea de tendencia lineal predeterminada es la mejor para predecir los beneficios.
Puede que incluso pruebes algunas líneas de tendencia más y descubras que la R-cuadrado (una medida del ajuste de la ecuación a tus datos) mejora con otras ecuaciones, elevando aún más el perfil de esta pregunta.
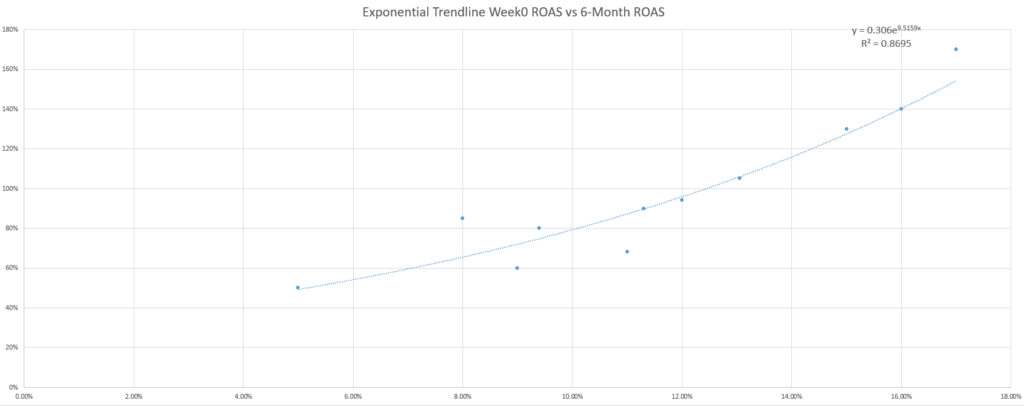
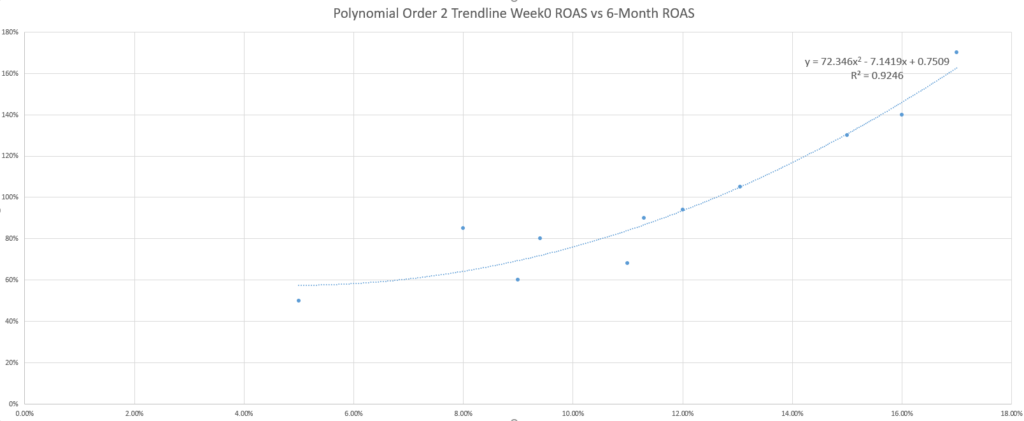
Aunque el adagio mercadotécnico de “depende” se aplica de nuevo a la hora de seleccionar la mejor línea de tendencia, otro adagio mercadotécnico resulta útil como respuesta: KISS (keep it simple, stupid, en español: Manténlo sencillo, estupido). Si no eres un estadístico o un aficionado a las matemáticas, lo mejor es que utilices las líneas de tendencia más sencillas, que son las lineales.
¿Por qué es un problema? Como ejemplo sencillo, considera la adición de datos inesperados en el modelo. En los dos escenarios siguientes, observa cómo afecta a la precisión de cada modelo de línea de tendencia (evaluada mediante el MAPE) un ROAS de la semana 0 más bajo que madura inesperadamente bien, o un ROAS de la semana 0 más alto que madura inesperadamente mal.

El uso del MAPE para comparar los distintos modelos basados en líneas de tendencia muestra que, aunque los modelos lineal y exponencial no son los más precisos en ningún caso, sí son los más coherentes.
Además, el aprendizaje automático puede ofrecerte la posibilidad de automatizar este proceso, analizar mayores cantidades de datos y proporcionar insights más rápidamente.
Asegúrate de ir por el buen camino
Como nota final, echa un vistazo a esta lista de preguntas adicionales que pueden resultar útiles para garantizar que tu análisis de predicción se forme sobre una base sólida:
- ¿Seguiste alimentando tu modelo para mantenerlo entrenado con los datos más relevantes?
- ¿Has comprobado si las predicciones de tu modelo se cumplen a partir de las nuevas observaciones, o casi?
- ¿Tienes demasiadas variaciones o, por el contrario, te sobran?
- Un R-cuadrado muy bajo o un R-cuadrado muy alto son indicativos de un problema en la capacidad de tu modelo para predecir nuevos datos con precisión.
- ¿Has utilizado el KPI adecuado?
- Sigue adelante y prueba diferentes KPIs (por ejemplo, más o menos días de ROAS o LTV) y utiliza el MAPE para comparar el poder de predicción de beneficios de cada uno.
Te sorprenderá lo poco correlacionadas que están las medidas estándar.
- ¿Han experimentado cambios significativos tus indicadores principales o tus primeros benchmarks?
- Esto puede ser una señal de que algo importante ha cambiado en el mundo real, y que se avecinan problemas para la capacidad de tu modelo de predecir los beneficios con precisión de cara al futuro.
- ¿Has aplicado la segmentación a los datos?
- Segmentar a los usuarios en grupos más homogéneos es una buena forma de reducir el ruido y mejorar el poder predictivo del modelo.
Por ejemplo, no apliques el mismo modelo a todos los usuarios de todos los canales y zonas geográficas si esos usuarios tienen tendencias de retención y costos significativamente diferentes.
- ¿Tienes en cuenta la influencia del tiempo?
- La mayoría de los profesionales del marketing son conscientes de la influencia de la estacionalidad como factor por el que las predicciones pueden fallar, pero el ciclo de vida de tu aplicación/campaña/público/creativo también puede influir en la capacidad de tu modelo para realizar predicciones precisas.

Una pieza más al rompecabezas: Predecir el LTV de los anuncios in-app
La publicidad in-app (IAA) se ha hecho cada vez más popular, representando al menos el 30% de los ingresos de las aplicaciones en los últimos años. Los juegos hipercasuales y casuales, además de muchas aplicaciones utilitarias, aprovechan naturalmente este flujo de ingresos como principal fuente de monetización.
Incluso los desarrolladores que dependían por completo de las compras in-app (IAP) han empezado a monetizar con anuncios. Como resultado, podemos ver que muchas aplicaciones están combinando con éxito ambas fuentes de ingresos para maximizar el LTV de sus usuarios.
Por ejemplo, no hay más que ver el Candy Crush de King.
El LTV de la monetización híbrida se compone de dos partes:
- Compras in-app/suscripción LTV: Ingresos generados activamente por un usuario que compra moneda del juego o de la aplicación, artículos especiales, servicios adicionales o una suscripción de pago.
- LTV de publicidad in-app Ingresos generados pasivamente por un usuario que ve y/o interactúa con anuncios (banners, vídeos, intersticiales, etc.)
El desafío de los datos
Idealmente, los marketers deberían ser capaces de comprender el valor nominal de cada impresión; eso la convertiría prácticamente en una “compra”. Tras recopilar suficientes datos, podremos crear modelos de predicción similares a los que ya hemos descrito en el capítulo 2 para las compras in-app.
Pero en el mundo real, no es tan sencillo: incluso calcular el LTV de los anuncios in-app por sí solo es difícil debido al volumen y la estructura de los datos de ingresos que los profesionales del marketing pueden tener en sus manos.
Por enumerar algunas cuestiones:
- Rara vez se muestra una única fuente de anuncios. En realidad, hay muchísimas fuentes, con un algoritmo/herramienta detrás (plataformas de mediación publicitaria) que cambian constantemente las fuentes y el eCPM.
- Si un usuario ve 10 anuncios, es muy posible que procedan de 5 fuentes diferentes, cada una con un eCPM completamente distinto.
- Algunas redes publicitarias pagan por acciones (instalación, clic) en lugar de por impresiones, lo que complica aún más las cosas.
- Cuando se trabaja con plataformas de mediación de uso común que ofrecen ingresos publicitarios a nivel de usuario, la cifra sigue siendo una estimación. Las redes publicitarias subyacentes no suelen compartir estos datos, lo que suele dar lugar a un reparto de los ingresos generados entre los usuarios que vieron las impresiones).
- Los eCPM pueden fluctuar drásticamente con el tiempo y es imposible predecir estos cambios.
Modelos de predicción de LTV de anuncios in-app
Muchas de las empresas entrevistadas no participan activamente en las predicciones de LTV de los anuncios. Entre los marketers de aplicaciones de juegos que se interesaron por el tema, ninguno lo tenía tan claro como para utilizarlo con gusto. En cambio, era más bien un trabajo en curso.
A continuación se exponen los conceptos que se debatieron como puntos de transición:
1. El modelo de retención basado en la retención/ARPDAU
- Concepto: Utilizando el modelo de retención ARPDAU, que en este caso también contiene la contribución adicional de los ingresos por publicidad in-app.
- Ejemplo: La retención D1/D3/D7 es del 50%/35%/25%. Tras ajustar estos puntos de datos a una curva de potencia y calcular su integral hasta D90, se obtiene que el número medio de días activos es de 5. Sabiendo que el ARPDAU es de 50 céntimos, la LTV prevista para D90 sería, por tanto, de 2,50 dólares.
2. El método basado en la proporción
- Concepto: Integrar las estimaciones de ingresos publicitarios a nivel de usuario en la pila para utilizar el método de la proporción del mismo modo (es decir, basándose en los coeficientes de D1, D3, D7, etc.).
- Ejemplo: El ARPU calculado tanto a partir de las compras como de los ingresos por publicidad dentro de la aplicación es de 40 céntimos después de los 3 primeros días. Sabemos que D90/D7 = 3. Por tanto, el LTV previsto para D90 sería de 1,20.
3. El método de la multiplicación simple
- Concepto: Calcular la relación entre las compras desde la aplicación y los ingresos publicitarios para utilizar un multiplicador para el cálculo del LTV total. Si se dispone de más datos, se pueden calcular múltiples coeficientes para las dimensiones de plataforma/país, ya que suelen ser las que más influyen en la relación entre ingresos por anuncios e ingresos por aplicaciones.
Enlace a las predicciones de LTV basadas en el comportamiento
Es importante mencionar otro factor clave que puede influir mucho en la rentabilidad potencial de los usuarios de aplicaciones: la canibalización.
Los usuarios que gastan dinero realizando compras dentro de la aplicación suelen tener un LTV significativamente mayor que los usuarios que sólo consumen anuncios. Es de suma importancia que su intención no se vea interrumpida por mensajes gratuitos de cosas útiles.
Por otro lado, es importante incentivar a los usuarios para que vean los anuncios, por lo que a menudo se les recompensa con dinero o bonificaciones dentro de la aplicación.
Si una aplicación contiene tanto anuncios con recompensa como compras dentro de la aplicación, es posible que, en un momento dado, un jugador que de otro modo se convertiría en un gastador de IAP no lo haga debido a una recompensa significativa de moneda dentro de la aplicación a cambio de ver anuncios.
Aquí es exactamente donde entran en juego las predicciones de comportamiento: midiendo el comportamiento de los usuarios, un algoritmo de aprendizaje automático puede determinar la probabilidad de que ciertos usuarios se conviertan en “gastadores” e indicar dónde es necesario realizar ciertos ajustes en la experiencia de juego/aplicación.
El proceso funciona de la siguiente manera:
- Todos los usuarios deberían empezar con una experiencia sin anuncios mientras se empiezan a medir los datos de compromiso.
- El algoritmo calcula continuamente la probabilidad de que un usuario se convierta en gastador.
- Si esta probabilidad supera un porcentaje establecido, los anuncios dejarán de mostrarse mientras se recopilan más datos (“esperar a la compra”).
- Si la probabilidad cae por debajo de un porcentaje establecido, lo más probable es que este usuario nunca realice una compra. En este caso, la aplicación empieza a mostrar anuncios.
- Basándose en el comportamiento a más largo plazo de los jugadores, el algoritmo puede seguir evaluando su comportamiento al tiempo que modifica el número de anuncios y mezcla entre distintos formatos.
La mayoría de las empresas se conformarán con utilizar modelos y enfoques sencillos que ofrezcan la mejor relación costo/beneficio, sobre todo en lo que respecta a las dificultades de aplicación y al valor añadido de unos insights más precisos.
Ya se observan rápidos avances en este ámbito, con diferentes soluciones que vienen a llenar los vacíos y complementar el frenético ritmo de desarrollo del ecosistema, así como la creciente importancia de la publicidad in-app como fuente de ingresos clave para las aplicaciones.
El método de cotización
Aunque los métodos de predicción del comportamiento bien afinados pueden dar los resultados más precisos a la hora de atribuir los ingresos publicitarios, existe un método más sencillo y viable para tratar la cuestión de la asignación de los ingresos publicitarios a una fuente de adquisición.
Este método se basa en asignar la contribución de un canal a los ingresos publicitarios en función de puntos de datos agregados sobre el comportamiento de los usuarios.
Los márgenes de contribución se obtienen convirtiendo la contribución de un canal al comportamiento global de los usuarios en el margen de ingresos de ese canal a partir de los ingresos publicitarios globales generados por todos los usuarios.
La teoría es que cuantos más usuarios adquiridos de un canal generen acciones en una aplicación, más influyente y merecedora será la mano de ese canal a la hora de reclamar el crédito por los ingresos publicitarios de esos usuarios.
Para aclararlo, desglosémoslo:
Paso 1
El primer paso consiste en seleccionar un punto de datos que se utilizará para determinar el margen de contribución a los ingresos publicitarios de cada fuente de adquisición.
Como punto de partida, puede utilizar la regresión de líneas de tendencia de Excel para identificar qué KPI de comportamiento del usuario se correlaciona mejor con los cambios en los ingresos publicitarios.
Ten en cuenta que, dado que el método de contribución implica la atribución de ingresos en función de una proporción de la actividad total, deberás utilizar un punto de datos que sea un número similar al recuento de usuarios activos en un día, en lugar de una tasa de retención similar al ratio.
Algunas opciones son:
- Total de usuarios activos
- Total de sesiones de usuario
- Duración total de la sesión
- Datos atribuibles a los anuncios (por ejemplo, impresiones de anuncios)
- Total de eventos clave (por ejemplo, partidos jugados)
Paso 2
Una vez que tengas unos cuantos puntos de datos para observar, haz un diagrama de dispersión de cada punto de datos contra los ingresos publicitarios totales por día para ver dónde son más fuertes las correlaciones entre los cambios en el comportamiento del usuario y los ingresos publicitarios totales.
Paso 3
Añade el punto de datos R-cuadrado a tu gráfico para identificar qué punto de datos tiene la correlación más fuerte.
Este método de regresión de líneas de tendencia de Excel tiene un inconveniente: cuanta menos variación haya en el comportamiento de los usuarios y los ingresos publicitarios, menos precisa será la capacidad del modelo para observar la fuerza de la correlación entre los puntos de datos.
Como resultado, tendrás menos confianza en poder elegir un punto de datos sobre otro.
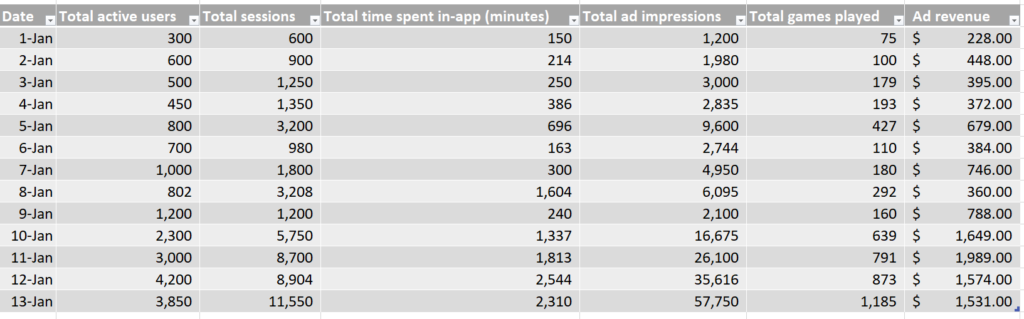
En este conjunto de datos simulados, vemos los recuentos de cada punto de datos, por día, así como los ingresos publicitarios totales generados por día.
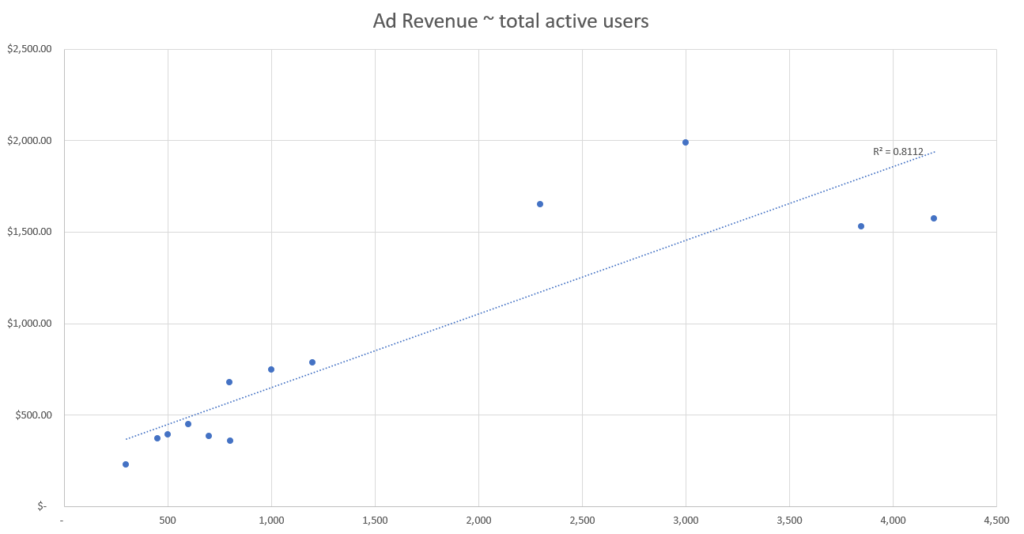
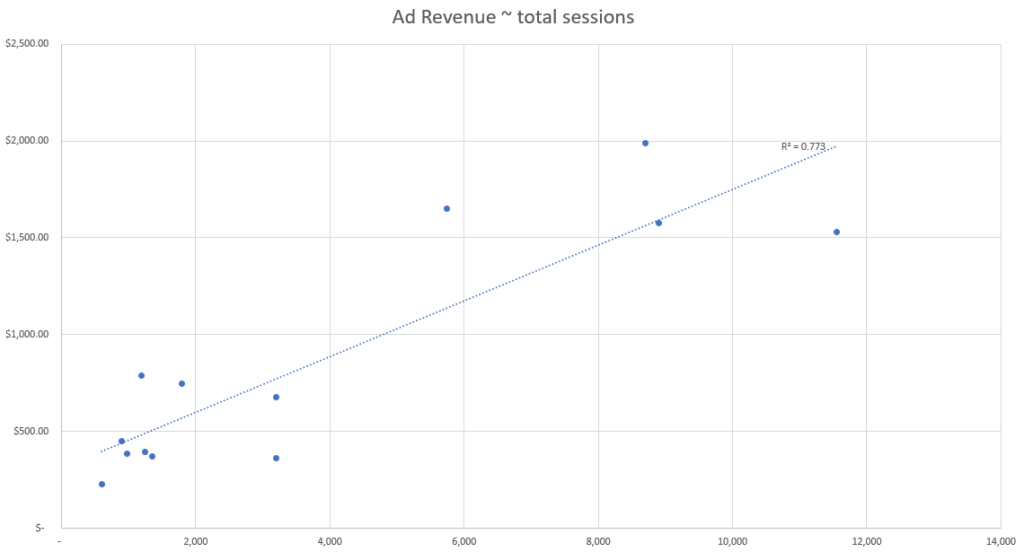
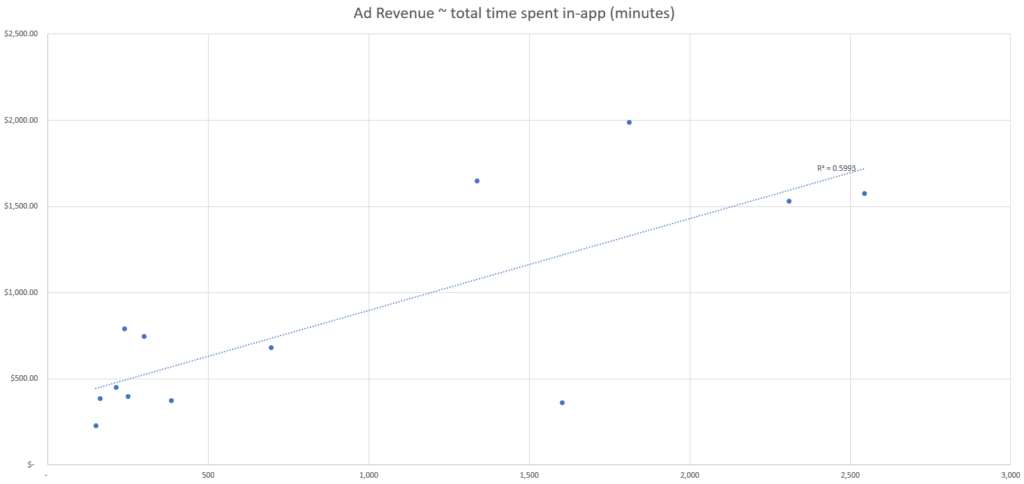
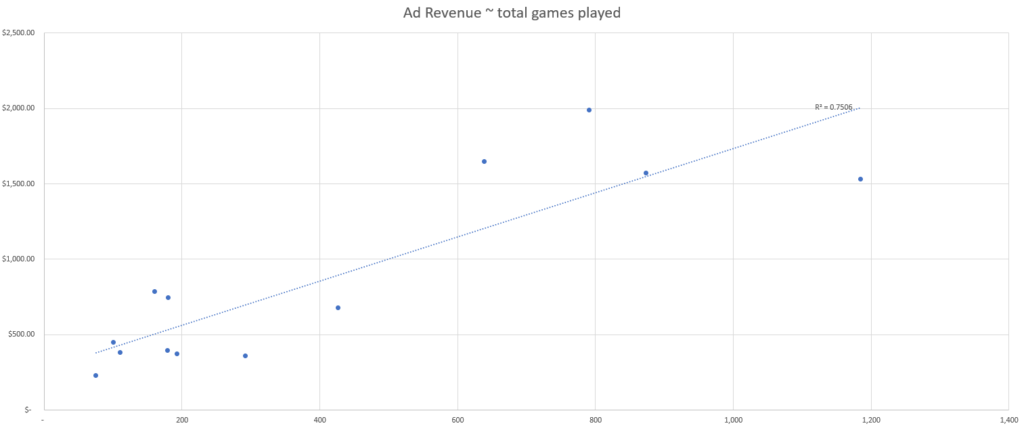
Basándonos en estos datos simulados, podemos ver que el evento con la mejor fuerza de correlación parece ser el número de usuarios activos según nuestra métrica de ajuste R-cuadrado.
Esto significa que el punto de datos de nuestro conjunto que mejor explica los cambios en los ingresos publicitarios es el número de usuarios activos y, por tanto, deberíamos utilizar el número de usuarios activos para atribuir los ingresos publicitarios por canal.
Paso 4
Una vez que hayas seleccionado un KPI de comportamiento del usuario, es hora de calcular el margen de contribución.
A continuación, multiplica el margen de contribución diario de cada canal por los ingresos publicitarios acumulados generados cada día.
Este proceso requiere que los datos de comportamiento de los usuarios se midan por canal y sean accesibles cada día, de modo que el margen de contribución de todos los canales pueda calcularse con los datos de ingresos de cada nuevo día.
Nota: aunque aquí sólo incluimos cuatro canales publicitarios con fines ilustrativos, es posible que también desees incluir aquí tus datos orgánicos y de otros canales, con el fin de atribuir completamente los ingresos diarios al comportamiento diario de los usuarios.
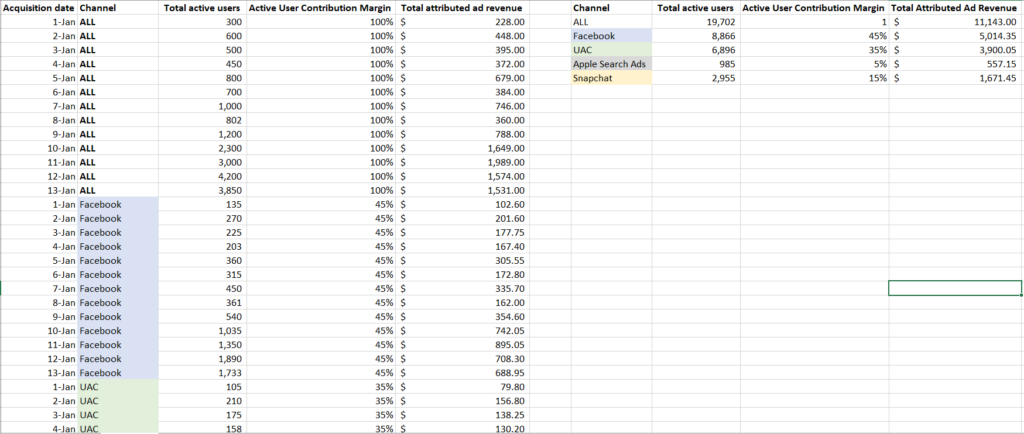
Arriba, podemos ver los ingresos publicitarios calculados generados por día, por canal, lo que te permite estimar la rentabilidad de cada canal.
Ten en cuenta que tendrás que revisar tu evaluación de los KPIs útiles para la atribución de ingresos publicitarios a medida que cambien las tendencias de comportamiento de los usuarios y los datos de monetización de los ingresos publicitarios, o a medida que dispongas de nuevos puntos de datos.
Por ejemplo, en el conjunto de datos anterior, podemos ver una segunda agrupación de puntos de datos hacia el final del periodo de datos (que comienza aproximadamente el 10 de enero), donde hay significativamente más ingresos publicitarios por día que a principios de mes.
Esto se refleja en la agrupación de los datos hacia la parte superior derecha de cada gráfico de dispersión, alejados del grupo inferior izquierdo.
Cuanto más complejo sea el conjunto de datos, menos precisa será esta simple evaluación de regresión de Excel y mayor será la necesidad de aplicar la segmentación y un análisis más riguroso.

Modelización predictiva en una realidad centrada en la privacidad
Hacia una nueva realidad publicitaria
El análisis predictivo te permite aumentar la audiencia potencial de tu campaña, impulsar un mayor LTV del usuario y garantizar una presupuestación más eficiente, en una era en la que, en algunos casos, ya no tenemos acceso a datos de rendimiento granulares.
La creación de diferentes grupos de características de comportamiento permite que tu audiencia no se clasifique por su identidad real, sino por su interacción con tu funnel en las primeras etapas. Esta interacción puede indicar su potencial futuro para aportar un valor significativo a tu producto.
La combinación de factores clave de compromiso, retención y monetización puede correlacionar la compatibilidad de un usuario con la lógica LTV de cualquier desarrollador, y proporcionar una indicación pLTV (Predicted Lifetime Value) desde el principio de una campaña.
Aprendizaje automático: clave del éxito
Una aplicación móvil puede tener más de 200 métricas disponibles para la medición, pero un marketer típico probablemente sólo medirá un máximo de 25. Una máquina, en cambio, es capaz de ingerir toda esa información en cuestión de milisegundos y aplicarla a las perspectivas de marketing y a los indicadores de funcionalidad de las aplicaciones.
Un algoritmo de aprendizaje automático podrá calcular todos estos indicadores y encontrar las correlaciones adecuadas para ti. Sus cálculos se basarán en tu definición de éxito, tu lógica de LTV, y la aplicarán a una cantidad significativa de datos para encontrar la correlación entre las primeras señales de compromiso y el éxito final.
Esto significa que los anunciantes ya no necesitan saber QUIÉN es el usuario, sino saber EN QUÉ perfil pLTV y características encaja. Este perfil debe ser lo más preciso posible y estar disponible durante los primeros días de la campaña. Debes representar los requisitos de LTV del anunciante para que se considere válido y procesable.
Cuando se trata de aplicaciones de eCommerce, por ejemplo, la aplicación de indicadores como las compras anteriores, la frecuencia de las compras, la hora del día o la progresión del funnel permite al algoritmo agrupar audiencias generales en cohortes altamente granulares y mutuamente excluyentes.
Esto permite una segmentación y una mensajería más eficaces y, en última instancia, un mayor ROAS.
Aprovecha las predicciones de LTV de los clústeres
Los análisis predictivos ayudan a reducir el periodo de aprendizaje de la campaña utilizando las integraciones existentes para proporcionar una predicción precisa del LTV de la campaña.
Aprovechando el aprendizaje automático y la comprensión de los datos agregados, el análisis predictivo podría proporcionar indicaciones sobre el potencial de una campaña en forma de puntuación, clasificación o cualquier otra forma de información procesable a los pocos días de su lanzamiento, informando a los profesionales del marketing sobre las probabilidades de éxito.
Por ejemplo, las máquinas de una aplicación de juegos descubrieron que los usuarios que completan el nivel 10 de un juego en las primeras 24 horas tienen un 50% más de probabilidades de convertirse en usuarios de pago.
Con esta información, los profesionales del marketing pueden cortar por lo sano con una mala campaña que no genera usuarios de calidad, optimizarla cuando sea necesario o redoblar la apuesta cuando los primeros indicios muestren un beneficio potencial, lo que les permite tomar decisiones rápidas de pausa-impulso-optimización.
El desafío de SKAdNetwork
La introducción de la realidad centrada en la privacidad de iOS 14 y SKAdNetwork de Apple ha creado su propio conjunto de desafíos, principalmente limitando la medición de datos a nivel de usuario en el ecosistema iOS a los usuarios que dan su consentimiento.
Se considera que este no es más que el primer paso hacia un entorno publicitario más centrado en la privacidad del usuario, y es probable que muchos de los principales actores de la industria en línea lo sigan de una forma u otra.
Estos cambios limitan no sólo el volumen de datos disponibles, sino también el margen de tiempo en el que los profesionales del marketing pueden tomar decisiones informadas sobre el éxito o fracaso de una campaña.
Aunque los algoritmos de aprendizaje automático pueden predecir rápidamente qué campañas tienen más probabilidades de proporcionar los clientes más valiosos, otras limitaciones son la falta de datos en tiempo real, la ausencia de datos de ROI o LTV, ya que mide principalmente las instalaciones, y la falta de granularidad, ya que sólo se dispone de datos a nivel de campaña.
Entonces, ¿cómo puedes ofrecer publicidad relevante sin saber qué acciones realiza cada usuario?
Lo adivinaste. Marketing predictivo basado en el aprendizaje automático. Mediante el uso de correlaciones estadísticas avanzadas basadas en datos históricos del comportamiento de las aplicaciones para predecir acciones futuras, los marketers pueden realizar experimentos utilizando parámetros no personalizados, como las señales contextuales y el entrenamiento continuo de modelos de aprendizaje automático.
Los resultados pueden aplicarse a futuras campañas y perfeccionarse a medida que se recogen más datos.

Mejores prácticas para crear modelos de predicción de marketing móvil
1. Alimenta a la bestia
Cuando se crean modelos de datos que se utilizan para orientar decisiones importantes, no sólo es importante crear el mejor sistema posible, sino también realizar pruebas continuas para garantizar su eficacia.
Para ambos fines, asegúrate de alimentar continuamente tu modelo de predicción de beneficios para mantenerlo entrenado con los datos más relevantes.
Además, comprueba siempre si las predicciones de tu modelo se cumplen a partir de nuevas observaciones, o al menos se aproximan a ellas.
No seguir estos pasos podría suponer que un modelo con un poder de predicción inicial útil se descarrile en función de la estacionalidad, la dinámica de las macro subastas, las tendencias de monetización de tu app o muchas otras razones.
Observando los indicadores adelantados o los primeros benchmarks y buscando cambios significativos en los puntos de datos, puedes calibrar cuándo es probable que tus propias predicciones también se vengan abajo.
Por ejemplo, si tu modelo se entrenó con datos en los que la tasa media de retención el primer día oscilaba entre el 40% y el 50%, pero durante el tramo de una semana, la tasa de retención el primer día cayó al 30%-40%, esto podría indicar la necesidad de volver a entrenar tu modelo.
Esto podría ser especialmente cierto si se tiene en cuenta que las señales de calidad de los usuarios que has adquirido más recientemente han cambiado, lo que probablemente provoque cambios en la monetización y los beneficios, en igualdad de condiciones.
2. Elige el KPI adecuado para predecir la rentabilidad
Hay varias opciones entre las que elegir, cada una con una serie de contrapartidas en cuanto a viabilidad, precisión y rapidez para producir recomendaciones.
Sigue adelante y prueba diferentes KPIs (por ejemplo, más o menos días de ROAS o LTV) y utiliza uno o todos los siguientes para comparar el poder de predicción de beneficios de varios KPIs:
- R-cuadrado
- Una relación éxito/fracaso en la predicción satisfactoria
- Error porcentual absoluto medio (MAPE)
Te sorprenderá lo poco correlacionadas que están las medidas estándar.
3. Segmenta tus datos
Segmentar a los usuarios en grupos más homogéneos no sólo es una excelente forma de mejorar la tasa de conversión, sino también un método probado para reducir el ruido y mejorar el poder predictivo de tu modelo.
Por ejemplo, si se aplica el mismo modelo a campañas basadas en intereses y a campañas basadas en valores similares, los resultados podrían ser menos eficaces. La razón de ello es que las tendencias de monetización y duración de la vida de los usuarios de cada objetivo de audiencia único probablemente sean significativamente diferentes.
La creación de diferentes grupos de características de comportamiento permite que tu audiencia no se clasifique por su identidad real, sino por su interacción con tu funnel en las primeras etapas. Esta interacción puede indicar su potencial futuro con tu producto.
Por ejemplo, un desarrollador de aplicaciones de juegos puede predecir el LTV potencial que puede obtener de sus usuarios en un plazo de 30 días. En otras palabras, el periodo de tiempo hasta la finalización de un tutorial (compromiso), el número de veces que se vuelve a la aplicación (retención) o el nivel de exposición a los anuncios en cada sesión (monetización).
4. No olvides tener en cuenta el tiempo
La mayoría de los marketers son conscientes de la influencia de la estacionalidad a la hora de desglosar las predicciones, pero el ciclo de vida de tu aplicación/campaña/público/creativo también puede influir en la capacidad del modelo para realizar predicciones precisas.
Las tendencias de los costos de adquisición en la primera semana del lanzamiento de una nueva aplicación serán muy diferentes de las del quinto mes, el segundo año, etc., del mismo modo que los primeros 1.000 dólares de gasto en un producto similar no explotado previamente serán diferentes de los 10.000 y 50.000 dólares de gasto invertidos en el mismo producto similar (especialmente sin cambiar la creatividad utilizada).

Hallazgos clave
Hallazgos clave
- La ciencia del análisis predictivo existe desde hace años y la utilizan las mayores empresas del mundo para perfeccionar sus operaciones, anticiparse a los cambios de la oferta y la demanda, prever cambios globales y utilizar datos históricos para anticiparse y prepararse para acontecimientos futuros.
- A medida que nos adentramos en una nueva realidad centrada en la privacidad, debemos adoptar una nueva norma de medición, que exija plazos de medición más cortos y aplique indicaciones anónimas sobre el potencial de los usuarios para la toma de decisiones.
- Los modelos predictivos hacen precisamente eso. La introducción de esta sofisticada tecnología en el panorama del marketing y su aplicación para adaptarse a la evolución del sector no es sino primordial.


